
Thomas D. Wason, Ph.D. (aka Dr. Tom)
http://www.tomwason.com [Home]
wason@mindspring.com
Gary Neely
Indiana University
(No Photo Available)Dr. Tom’s Guide to a simple path to Meta-Data implementation
|
One of the Dr. Tom Guides |
Purpose of Document
To describe a simple path to start using the IMS meta-data specification. Ways to break implementation down into manageable parts are discussed.Contents
- 1. Introduction
- 2. Breaking Down the Problem
- 3. The Data Base Problem
- 4. Selecting the Fields
- 5. Populating the Fields
- 6. Quality Control
- 7. Creating the XML Record
- 8. Develop an XML meta-data library
- 9. Searching
- 10. Staged Start
- 11. Summary
1. Introduction
We frequently hear the question:
- "How can I start using the IMS meta-data specification? I have a low budget and my users know nothing about XML."
Your enterprise has decided to implement the IMS meta-data specifications. You've just been informed you will be responsible. You don't know XML. You don't know what information must be cataloged. You don't know who will eventually do the cataloging. You don't know how your enterprise will use your meta-data. What you know is that you are expected to present a plan of action to your enterprise, and the deadline is approaching. You need a simple plan to implement the IMS meta-data specification, and you need it now.
Sound familiar? We've been working with a team that is developing the Learning to Teach with Technology Studio (http://www.ltts.org/). The LTTS is a FIPSE (Funding for Improvement in Secondary Education) supported project at the Center for Research on Learning and Technology at Indiana University. The LTTS helps in-service and pre-service teachers learn to integrate technology into the classrooms. A significant effort is the development of short learning modules to teach the teachers, as for-credit online instruction will be available. The teachers will create learning modules that will be available through the LTTS. The learning resources, both for teachers and for learners, will have IMS meta-data. Resources are limited. In the process of assisting with the meta-data implementation process, we demonstrated that an implementation can be simplified to a series of easily-handled steps. At this point LTTS is in the planning stages on its meta-data implementation. Gary Neely is responsible for the technical aspects of implementation, and has co-authored this guide with me.
We'd like to show you the details of how we approached the problem.
The main concepts we'll illustrate are:
- Divide and conquer.
- You won't get it right the first time.
- Write things down.
- Start.
Your first goal is to break your problem down into smaller tasks. This "divide and conquer" method allows you to solve the problem one step at a time. Small tasks are more easily completed and no one is overwhelmed by the challenge. Small steps also allow you to delegate portions of the problem should you have the resources available.
Don't be alarmed if you don't get your solution right the first time. You probably won't. Plan on it. The meta-data will evolve, and you must decide how you will support legacy meta-data records you have already created. As a general rule, don't change things too fast. Live with what you have for as long as you can and let practical applications determine your needs. System administrators will love you for this. Start small: it's much easier to increase the number of the meta-data fields, but much more difficult to reduce the number of fields. If you reduce the number of fields, what do you do with the fields in the existing records? That information may need to be captured in other fields.
Remember to write things down. Write down definitions. Write down scenarios. Write down ideas for what needs to be meta-tagged. Keep notes of conversations and keep records of interesting related web sites. Consider setting up an internal web site or other information forum so that your team can look at your documents as they are developed. This can be a great source of ideas in addition to records of your work.
Finally, start now. Make it real as soon as you can. Approach this from the standpoint of what the software industry calls Rapid Application Development (RAD). This will give you feedback early in the process, and will get things up and running. Start small and grow your implementation. Remember, one of the guiding concepts is that you won't get it right the first time:
So
start as soon as you can!
2. Breaking Down the Problem
Let's start by breaking things down into major tasks. The major tasks identified for this project are:- The Data Base Problem
- Selecting the Fields
- Populating the Fields
- Quality Control
- Creating the XML Record
- Develop an XML meta-data library
- Searching
- Staged Start
Each of these tasks really addresses one or more questions.
3. The Data Base Problem
The IMS specifications are for moving data across some sort of network such as the Internet. They do not define how data are stored and retrieved. The data base problem refers to which fields should be in your data base. How do you structure your data base?In addition to budget and human resource constraints, one of the first considerations was putting the meta-data into a data base. The IMS Meta-Data specification does not address data bases: that is a local storage problem. The IMS specification is for the transport of meta-data. We could simply say "Local storage is your problem", but that's not very helpful, is it? The problem is manageable. LTTS said it wanted to have meta-data that directly corresponded to the IMS specification, meaning that the fields in their data base would correspond directly with fields in the meta-data XML record. This is reasonable. It also makes the easy implementation even easier. In short, we recommend using the IMS meta-data specification to define the actual meta-data you will have in your data base.
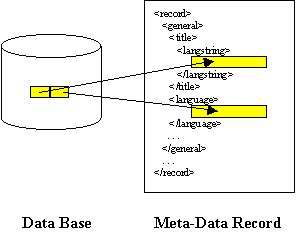
Data base fields that map to record fields.
To state it simply, LTTS decided to use the IMS Meta-Data specification as a basis for the fields to be stored in its data base. The definitions for the fields provided by the IMS Meta-Data specification are being used. The development of solid definitions is a potentially contentious process. IMS has gone through this process carefully with representation from many domains and countries, so the definitions are considered useful widely. Stick with them. Usefulness is the fundamental purpose of the meta-data. It is the key to all of the IMS specifications.
We've discussed what the relationship between the meta-data and the data base can be: a 1:1 mapping. You have solved the problem of what goes in the data base. That still doesn't tell you what to put in the data-base. Patience, we'll get to that. As you will see, you might decide not to put all of your meta-data in the data base, but keep it in XML records.
4. Selecting the Fields
The IMS Meta-Data specification provides a lot of fields. You probably don't need them all. You may need to capture some information that doesn't seem to be contained in the IMS fields. How do you select the right fields to use?
What is the meta-data to be used for? Select only those fields that have a purpose. Start with a slim set of fields, and build later. Remove the fields you don't need from your meta-data model.

Remove unused meta-data fields.
The technical people want to keep it pretty simple, the users imagine all sorts of future scenarios. Different constituencies within this project have different needs. The LTTS project is large, and includes major organizations beyond the academic institution, some of which have commercial interests. The community naturally divides according to the kinds of scenarios they envision. We discovered this and used it. Again, divide and conquer.
Your team can operate in two modes. In a "small group" mode the team is divided into several small groups. Each group is focused on a particular task. In the "big group" mode the entire team meets to determine the small group tasks and review the results of the small groups' work. Small groups can move quickly; they can also wander off track.
The users are divided into groups to select the fields they feel are important. Small groups can come to conclusions rapidly. You can have the users self-select the group they will join, or they can be assigned. The objective is to have each small group focus on a narrow part of the complete selection from one particular orientation. People no longer will feel that they have to address the whole selection problem; they need only deal with a small area. This is an ideal approach. In reality, because getting a system started had a much higher priority that getting it right, a preliminary set of meta-data was selected by the core team members. This emphasis on "getting started" is the right one, in Dr. Tom's experience. More about that later.
However you select meta-data, use scenarios. A scenario is a description of some real or anticipated course of actions. Get the scenario written down! A scenario does not have to span everything, but may be some small fragment. For example, what happens when a student decides to take a course? How does the student now that he or she is elligible? That the right prequisites have been fulfilled? How does the student register for a course? How does a student know what sort of payment may be required? You are addressing only the process of signing up for a course in this scenario. What meta-data is needed for each step? When all of the groups are through, pool (combine) the selected fields. Review all of the scenarios: often listening to another group's scenarios will trigger revision of your own.
Invariably, some needed fields appear to be missing. Take a three-pronged approach here: 1) inspect the definitions of the needed fields and try to compare them with the definitions of existing IMS fields; 2) investigate using the classification category, and 3) extend the IMS meta-data.
Gene Alloway of the University of Michigan advised us to take a definition-centered approach, and it has worked remarkably well. Write down the definition for each field you feel you need. Start with each IMS field that appears to be of use to you; adopt that definition without revision. You may want to add your own explanatory commentary. Add the definitions of additional fields you feel you need.
Often a careful inspection of the definitions of the existing IMS meta-data fields will reveal that the name chosen for a field does not match up with what the group might select, but that an IMS definition is quite close. This is not really surprising, as the IMS meta-data, which are derived directly from the IEEE Learning Technology Standards Committee Learning Object Meta-Data, were developed by a large number of people, so some may have needs similar to yours. Ignore the name of the field. It is only a token to access the field. The token name was often selected by an international committee, and was chosen to have the least confusion on that scale. Adopt an IMS Meta-Data field whenever possible.
A great deal can be accomplished using the Classification category. I urge you look at the guide to classifications: drtomclassification.html
You still may find that you would like fields that cannot be accommodated with the IMS meta-data specification. You can extend the IMS meta-data. However, as you are just starting your system up, put these extensions at a low priority, if at all possible. Leave them until later if at all possible. Actual practice always changes your thinking on what you need, so leave out as much as you can. Really! As Eliot Christian of the U.S. Geological Survey and spark plug of the Government Information Locator Service (GILS) project is fond of saying, "Any meta-data is infinitely better than none". You don't need a lot to have something useful. It is possible to extend the IMS meta-data. Wait.
5. Populating the Fields
Once you have selected the fields how do you fill in the data? Who does it? How do you actually get the data entered someplace where they can be stored? How do you populate the fields selected?How do you get the data for the meta-data fields? If you think of entering all of the meta-data in one shot, it can be daunting. This raises the question of who will enter the meta-data. How do you find or train adequate catalogers? The key to populating the fields was to look at the work flow in the creation of a learning module.
The LTTS module production process has been broken down into five steps:
- Submitting Your Proposal
- Building Your Module
- Testing Your Module
- Submit Your Module to LTTS
- Finalize Agreements
Each of these steps provides a logical opportunity to add or edit meta-data fields. LTTS can break the meta-data creation into five steps. A five part form of sorts can be created. [Not too subtly, there's that "divide and conquer" again.] Each step in the development of a resource has a set of fields associated with it. A document template, such as a Word template, can be created to support the form. The meta-data form is part of the module development process. The person responsible for each step contributes to the meta-data fields as appropriate. The names of the fields in the form can be different from the actual element names. Pick names that your users will be comfortable with.

A sample Meta-Data entry form
The meta-data form also constitutes part of the work-flow management. For example, during the submission phase, the intended end user characteristics, prerequisites, objectives, working title, subject domain, duration and platform requirements may be entered. At each step the product can be evaluated with respect to the meta-data created. Projects often change as they develop a life of their own during development. One can then ask if the module and its meta-data are in accord. If not, what is to be done about it? You can manage and record your decisions via the meta-data form. The objective is to develop the meta-data while developing the module. It is part of the work process, recording intent and results.
6. Quality Control
Once the data have been entered into the meta-data fields, how do you ensure that they are good meta-data? How do you set up some sort of meta-data quality control process?Quality control is a process for ensuring that what you are producing is good. The idea of quality control of meta-data can raise apprehensions. Are we talking about ISO 9000? Quality Circles? Quality Assurance? You can have as much or as little as you like, but have some. Have a plan. Remember, anything is far superior to nothing. Other organizations will value--or de-value--your meta-data based on their experience with its quality. If your meta-data is considered to fairly and accurately characterize your resources, then it will be used. If not, it will not be used. This judgement will be made against your entire repository of meta-data. Any quality control will put you a large distance ahead of most other efforts. A quality control effort will also let you assess how well your development process is under control.
There are several strategies that you can adopt for meta-data review. You can break it down into logical subgroups and have people evaluate appropriate fields. For example, a technical group might simply test to ensure that the resource will operate within the specified environment and determine the straight running time of the resource, if applicable. Again, divide and conquer.
One of the biggest effects of a quality control program is that developers know that their work will be reviewed, so they perform accordingly. Therefore, ANY quality control program will have a positive effect.
7. Creating the XML Record
Once you have captured the data for the fields, how do you put that into the correct XML format? How do you go about creating the meta-data XML record? Someone's going to have to know some XML: who?At some time, somehow, the meta-data will need to go from the form fields into an XML record according to the IMS meta-data binding specification. How does this happen? The first important thing you have done is to separate the generation of the meta-data from its coding in XML. Divide and conquer: have we made the point? If one person does this XML mapping, then only one person needs to know anything about XML. [You may want to look at the Guide to XML on the IMS site: drtomxml.html]. The mapping can be accomplished by an individual with an XML editor, an empty instance of the meta-data record, a "map" and the completed form. Cut-and-paste can be used to transfer the field data from the form to the XML editor. This is not a fancy way of doing things, but it gets you making meta-data quickly while using only one person to know how to do the mapping into XML. It also lets you get immediate experience with your meta-data. Use of a validating editor ensures that the XML binding is correct.
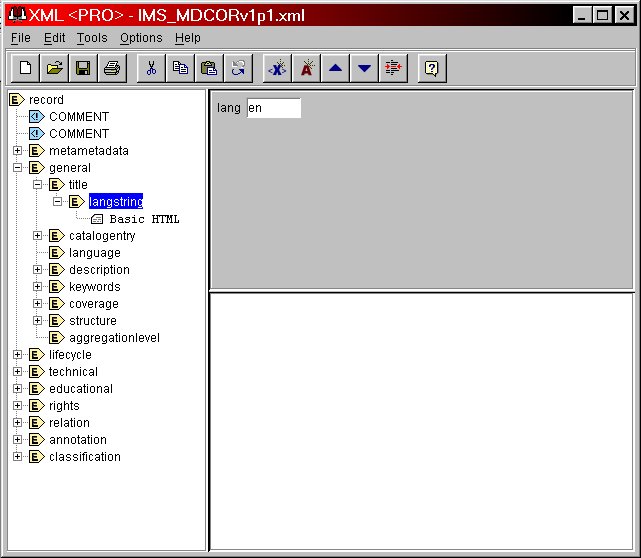
XML Editor for data transfer
Let us return to the data base problem. If the meta-data has been created such that it maps directly into a data base, then it should be a relatively simple operation to map the data base fields into the XML with a program. At a more advanced state of development, you may want to capture the meta-data directly into the data base. But wait, get some experience first. Also, when you read about searching, below, you will see that there is another alternative: store only a small subset of the meta-data in the data-base.
8. Develop an XML meta-data library
Once you have created the methods for creating meta-data records in the IMS Meta-Data Specification XML binding, it is time to build a library of meta-data records. These will comprise a resource that you can start building right way. You should not wait until you can populate a searchable data base. The meta-data creation will become an integral part of resource creation. The module authors will become familiar with the process.
9. Searching
One reason for making meta-data is to allow people to discover your resources. How do you enable searching of the structured meta-data?Searching structured data can require rather elegant search systems: not something you want to undertake when getting started. It would be convenient to have a small number of flat fields that can be quickly searched. That's a good way to do things: it has been suggested by several vendors. Don't open up the entire set of meta-data for searching. Instead, select a small number of fields and map them directly into a flat data base. Store the XML record of the entire meta-data in a file. When someone searches the small set of fields and requests the meta-data, you just blindly ship out the entire XML record file. Obviously you will have to accommodate edits of the meta-data. If edits are always done on the complete record, and then flat fields are regenerated from the record, synchronization should be manageable.
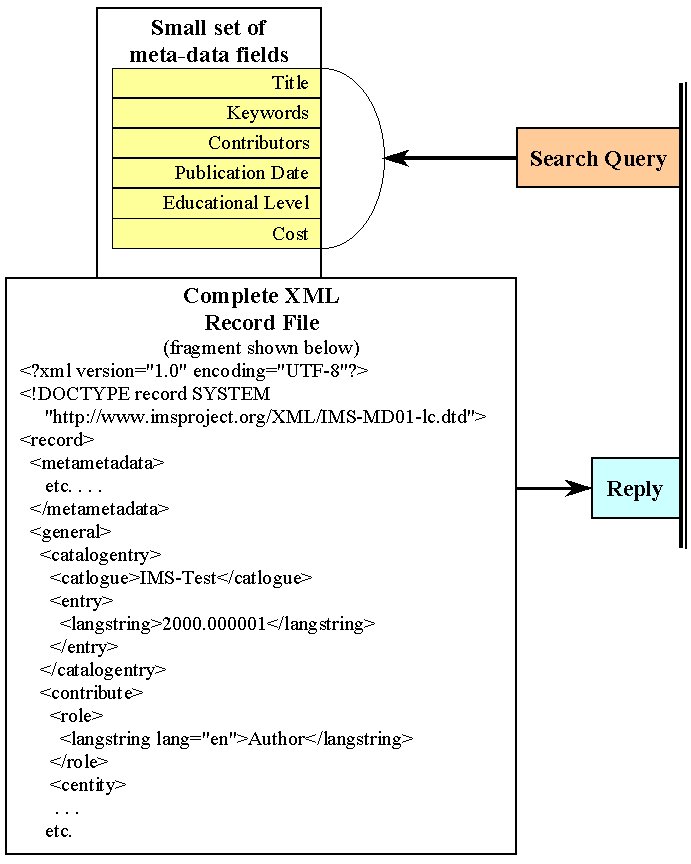
A simple search strategy
The objective of this approach is to create an easy point of entry in implementing a search system. Another objective is to make it as easy as possible for your users. If they are confronted with a few fields they can formulate a search more easily. As Linda Hill (U.C. Santa Barbara) has said, discovery and description are different things. Simplified meta-data helps discovery.
10. Staged Start
It's too a big jump to start up the entire meta-data generation system in one step. How can you start up a system in reasonable steps?
You have a lot of pieces: now where do you begin? One of the first things to do is to create a simple system for capturing meta-data. It makes little difference what that meta-data are at the start. I know, that sounds like heresy, but anything is so much better than nothing. You need to work the bugs out of the meta-data collection process first. So don't present your people with two problems: What does this field mean? and How do I enter it? Select a small number of trial fields as a starting point. It's easier to add than delete.
- Stage 1: A small beginning.
- Select a small number of meta-data fields.
- Create a document template for a meta-data entry form.
- Create a simple meta-data review process.
- Create an empty XML meta-data record that contains only the fields you have selected using the IMS DTD or XML-Schema.
- Create one complete sample form with meta-data values in every field you have selected.
- Review the meta-data. Adjust if you must.
- Teach someone how to move the data fields from the form to an empty XML record using an XML editor.
- Make a directory linking record file names to module titles.
- Store the resulting XML record.
- Write a meta-data entry instruction guide for your users.
- Make a small library of XML records.
- Stage 2: The data base.
- Define the searchable record. Will it be a few fields or a few buckets that aggregate fields?
- Create the database record structure.
- create a method for mapping or aggregating the XML record fields into the data base records.
- Populate the data base from the XML library.
- Stage 3: Searching the data base.
- Develop the search interface.
- Use test the search interface.
- Deploy the search interface.
11. Summary
No step in the staged development is rocket science. At the end of the first stage, you are actively developing a library of meta-data XML records. These are in the XML format that conform to the IMS specifications for the exchange of meta-data. This is the format in which you will receive new meta-data records that you will add to your data base. These records are in the format that the various departments of your enterprise will exchange meta-data. This library is a resource that your data-base developers can use during development. The library brings you into the world of meta-data. You are accumulating meta-data records for later use. If you choose to accomplish only stage 1, you have done a good job in your implementation of the IMS meta-data specification.
Creating the data base and developing search tools can proceed with less pressure because you are already collecting meta-data. Your data base experts know far more about this than Dr. Tom--we've just tried to give them resources and time to work. The selection of fields versus buckets can be decided without affecting the meta-data collection.
At the end of the staged development you don't have a complete and wonderful system. You can expect to run into problems when you scale this up. You will find that you need to alter your selection of meta-data fields. You can manage these changes in a reasonable manner, as you have a system up and running. You are storing your meta-data records in the IMS XML binding, so you can import them into newer and better systems.
Many of the terms in this guide are defined in the Glossary.
Authors:
Thomas D. Wason, Ph.D. (a.k.a. Dr. Tom)
wason@mindspring.com
Gary Neely
Indiana University
grneely@indiana.edu
wason@mindspring.com
Gary Neely
Indiana University
grneely@indiana.edu
Document Information
| Title | Dr. Tom's Guide to a simple path to Meta-Data implementation |
| Author(s) | Thomas D. Wason; Gary Neely, Indiana University |
| Version Date | November 2000 Current version 1.0 |
| Copyright | Copyright © 2000 IMS Global Learning Consortium, Inc. Used with permission. |