Contents
1. Summaries
The
reader is presumed to be aware of the ADL’s Sharable Content Object
Reference Model (SCORM).
1.1. Executive
How
are valuable instructional assets to be managed for effective course
development? How can these assets be reused to produce a good return on
the investment made in creating high quality instructional resources? How
can instructional designers create effective courses with a minimum of
technical knowledge? How can the potential for reuse be maximized? How can
this be done using the existing, proven SCORM standard?
This
paper presents a plan for creating stand-alone instructional objects
(IOs). IOs are designed to be autonomous so they can be used--and
reused--in various contexts. They can be placed in courses without
conflicting with other resources in the course. They are encapsulated
instructional objects. This document presents this concept in the specific
case of the ADL’s Sharable Context Object Model, SCORM. The Sharable
Content Object, SCO, is a specific instance of an instructional object.
This SCO model can be used within both SCORM 1.2 (unsequenced) and SCORM
2004 (sequenced) courses.
Courses
can be reduced to finer levels of granularity. Standalone SCOs can be
managed as assets within both business and instructional inventories. They
can be individually version controlled. They can be used by other
enterprises with a little modification. Their use can allow work flows that
are more effective.
1.2. Technical
A
course is an assembly. Similarly, a content package is an
assembly. A course is experiences that flow in a managed sequence.
Currently most experiences are media presentations to the learner, for
example an interactive web page or Flash object. The instructional flow
determines how the learner moves through these experiences. The
experiences are embodied in instructional objects (IOs).
Instructional designers need to be able to develop, gather and arrange IOs
freely to accomplish instructional objectives. IOs need to be
encapsulated units. An object can be a consistent and
reusable unit. How can we make IOs that can be manipulated as independent
objects?
Can a
SCO be an IO? How can we define a SCO structure that can most readily be
converted into an object? A SCO is a resource in an XML
manifest that points to files needed to execute the resource’s
behavior. The resource needs a unique identifier
(UID), e.g., identifier="R_123456". To be
reusable, the files need unique indicators. This can be accomplished by
putting all of a resource’s files in a subdirectory with a unique
name, e.g., R_123456. A reference to a file is made by prefixing the
subdirectory path to the filename when referenced: href="path/filename.xxx". The base attribute can be used at the
resource level, e.g., <resource
base="R_123456/">, to define the path for all files in the
resource. Basic metadata should be included. A simple example of a
manifest is provided in Section 13. This guide is consistent with
the requirements in SCORM 2004 3rd Edition
Content Aggregation Model (CAM).
What
follows is a rationale for these recommendations with implementation
notes. Some ideas outside of the specification per se have been
added.
2. Why? Q&A
Here
are some questions provided by Ohad Bukai and answers addressing the
purpose and use of this guideline:
Q:
SCORM is a mature standard, possibly giving way to a new one. Why develop
best practices now? What is the motivation for doing this?
A:
"Mature" is not the same as "static." Standards change. The way they are
used changes. An objective of this guide is to provide a structure that
will ease alignment with a new standard. This can be called "forward
legacy." The idea is to create a method that adheres to the
current standard while providing a reasonable chance of being able to
convert the results of the current standard into a new one. A uniform way
of pseudo-encapsulating the SCO is a step in that direction. Use of the
current standard should not be blind to the future. A method of
constructing SCOs such that they can be readily converted to and from
existing standards, such as S1000D, is also valuable.
The
latest guide from ADL, "ADL Guidelines for making reusable content with
SCORM 2004," makes no recommendations as to how the packaging of SCOs
should actually occur. That guide is pedagogically oriented. Here, we
ignore pedagogical considerations. This is a technical
guideline. This presents a uniform method for realizing SCOs that
should support development work flows and still be compatible with SCORM.
Q:
New emerging standards address the packaging question in a general way
(mpeg 21, common cartridge) ... why bother looking back?
A:
See above. The closer one is to being able to have one’s materials jump
forward the more it helps the current specifications to be adopted. It
also allows developers to be confident in the use of the current standard.
Current implementers want to see a pathway forward for their investment.
To repeat, "forward legacy." The objective is not only to implement
SCORM better but also to have a method that is more SCORM 1.x independent.
Q:
Packaging is a transient representation. Once the package is received by
an LMS, the LMS has a prerogative to select how to represent content
internally.
A:
"Transient representation" is a problem. How can you reuse something that
is not engineered for reuse, but changes? The existing standard works and
has been proven. The intent is to build on that strength. The crucial bit
here is creating a package that is consistent. An objective is to
support automatic management of SCOs. This means the use of tools and
utilities. This requires consistency in their representation, minimizing
ambiguity. An underlying goal of SCORM has been "reuse." It has not
succeeded at the level hoped for. First, there is no such thing as an
actual SCO. How can they be reused if there is no "there there?" The
objective here is to provide SCO autonomy. No one is required to do
things this way; it is only a proposed best practice. However, if LMS
developers state that they will take this format preferentially then they
encourage developers to do so. LMSs could use the carrot of servicing
potential course delivery in other standards formats.
The
real issue is not the LMS. It is what happens when an LMS is NOT in the
loop. The LMS in the loop model is a conceptual handicap. I search for
SCOs. I get SCOs. I should be able to drop them into a package with
minimum effort. If I have to decode different interpretations then the
work load goes up and reuse declines. Another problem with reuse is
sequencing. Right now organizations run from it, using Flash and its
counterparts. If you can separate SCOs from sequencing in a clean way,
then perhaps developers will be more inclined to use sequencing. This
guide does not address sequencing.
Q:
Someone might claim that the selection of package structure is a
prerogative of the author and is related to his organizations’ business
process. Who are we to say that our way is better? Why not live and let
live?
A:
Again, no one is forced to do this. Best Practices are not requirements
but are intended to foster a uniform interpretation of the
specifications. This is what really helps the adoption of a specification.
The use of large Flash objects is simply a de facto way of ignoring
the specifications’ potential for content reuse at a fine grain while
supporting adaptive sequencing.
Q:
Some practices must have been developed over the years by organizations
that make instruction. Can you reference what is the practice is?
A:
A good point. We developed the subdirectory concept within IMS
years ago, initially for packaging large numbers of student records. The
method was recognized as a way to package anything for safe transport that
allows disaggreagation at the receiving end without filename collisions.
It works. The recent ADL SCO Guideline stands mute on this. This has been
discussed with a few others who independently arrived at similar
solutions. We want to move from "similar" to "same" to support the
automated content management mentioned above. Uniform naming with UIDs is
not a handicap but a help. That is not required either.
Q:
The use of base: We don’t know
if the use of the base attribute is widely supported by LMS, if not, it
might be risky to suggest using it.
A:
True. However, the use of base
is in the SCORM specification. It has been around for a long time. One
must presume that such a fundamental specification has been implemented.
The use of subdirectories is far more important than the use of base, but base makes the <resource> reference
consistent. Base makes resource
(SCO) management easier. One could also develop automated processes for
deriving a new SCO from an old one through assigning a new GUID and
changing the base.
Q:
Uniform use of directories: If the package contains a large media file,
the packager may want to reuse it across two resources in the same
directory.
A:
True, SCORM has a solution to this, <dependency>. The
intent is not to prevent the common use of common files. This is
optimization. Optimization is a separate issue. It should be
treated as such. There is a difference between a standard and an
optimized content package. One edits course assembly in its
standard form. If one is to create a reusable SCO then one needs to
include all of its guts in the SCO’s "package." Otherwise it is not really
reusable or autonomous. Managing it means having to detect
and control its technical context of support and control files. As
repeated here, uniformity increases utility. It is also true that
with fine-grained structuring of a course, it may be reasonable to put the
large media file in its own SCO and put contextualizing SCOs around it in
the <organization><item>s.
You can then reuse that media SCO as many times as you like without
duplicating it. You are reusing the SCO within the course. A
course that has been developed using the reusable SCOs can be optimized.
This is a utilities or tools issue. A utility can optimize a
course by using subdirectory locations, filenames, checksums and hrefs.
Q:
The use of a metadata file rather than tag may be a comfort for some and
burden to others. There should be a strong case to suggest preferring it
to using the tag.
A:
A tag is an html attribute. It is not part of a SCO but is contained
within the html structure of a file in a SCO. Metadata is a well-defined
data structure that can carry information of use to many parties. Metadata
allows SCOs to be stored, searched and retrieved. It is a key to
reusability. Eventually it should be possible to encrypt a (zip, cab, jar
etc.) file such that only specific content (files) can be accessed, making
only the metadata available.
This
is a suggestion not a requirement. Perhaps the issue is the use of a
metadata file rather than in-line metadata. The objective is to create a
modularized SCO: resources (manifest style), files, and directories. As
much content is removed from the manifest as possible to separate what it
is from how you use it. Metadata is considered by some as a valuable
resource in itself, for instance in search systems. If one can expose and
transmit just the metadata, the IPR of the content is maintained.
Additionally, if one is going to use the SCO in some other form supporting
some other specification the conversion is simplified. People don’t have
to adopt all of the best practices. The use of metadata at the SCO level
is strongly encouraged.
Q:
Resource by reference - resources can reference files also by URI. There
should be some unified way to address the two, no suggestion here.
A:
According to the W3C XML Base document a URI is a local, base directed
reference unless one uses an absolute reference of the form http://...
This would really be a pain when the course is located in some unknown
directory.
3. A SCO defined
If I ask you to send me a SCO, what do you send
me?

Figure 1. A SCO
This
simple question has deep implications both within the community of current
adopters of SCORM and relative to other specifications, current and
future. These other specifications include S1000D, DITA, IEEE LTSC and
IMS. In short, the SCO is not an actual independent object. Can it
approach being one? Yes. The objective is to use the proven existing SCORM
standard to increase SCO robustness, reuse and a SCO economy.
Let
us illustrate the issues with a simple linear course (Figure 2). This
course is constructed of a series of items (1, 2, 3) for example
instruction, quizzes, media, whatever. The course structure of items is a
skeleton, or what Don Holmes (iMediaIT) describes as a "wire
frame." The items define where an instructional experience will take
place in the flow of the overall experience.
Figure 2. Simple course
Within
this linear SCORM course, each item has one instructional element (Figure
3). The instructional element provides the actual instructional experience
that is the "leaf" of a terminal item in the manifest’s organization
hierarchy. These instructional elements are SCOs. This separation of the
structure of the course, its wire frame as Don would say, from the actual
carrier of the experience allows the instructional elements to be complete
units. These units can be reassembled within other course structures,
reused, bought and sold as individual elements. This requires that these
elements be separable from the overall structure and still able to operate
in a new structure.
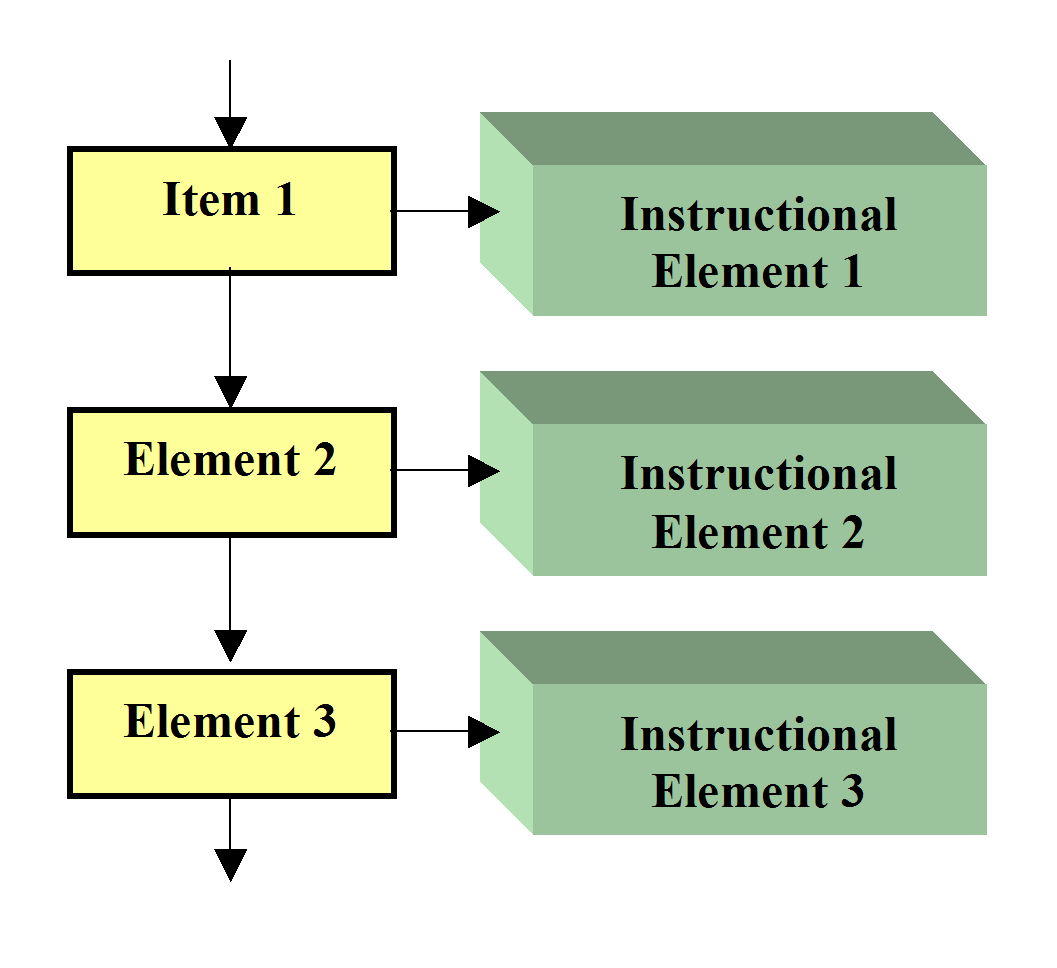
Figure 3. Items using
instructional elements
3.1. The instructional
object
Let
us consider the general form of an instructional object (IO) before
turning to a SCO approximation of an object. We are using the term
"instructional object" to indicate a general case. An instructional
element can be an object, an IO. From the standpoint of an instructional
system, an IO encapsulates data and processes. It has what
it needs to operate. It can be used in a variety of circumstances. It is
effectively autonomous. Autonomous does not mean that it can
function in isolation. It functions within a context. That context
can be an instructional experience delivered or managed by a system such
as a learning management system. The instructional context gives us some
relevant examples. IOs typically carry some media files to be presented to
the learner. The IO works in the context of a lesson or course.

Figure 4. Instructional element as an object
An
IO typically contains one or more files (Figure 5).

Figure 5. Instructional object
may contain files
An
instructional object may communicate with things outside of itself such as
the media, other files and items on the Web (Figure 6). Collectively all
of this stuff, internal and external, can be referred to as "content." It
may communicate with a learning management system (LMS). Conceptually all
of this is encapsulated in the instructional object. If you send me an
instructional object, it encapsulates all of this content and
capabilities. Such an encapsulation also supports intellectual property
rights (IPR) methods.

Figure 6. An instructional
object may reach beyond itself
The
use of instructional objects as reusable objects presents potential
problems. The IO is embedded in a context. The developer may have
made assumptions about the context. These assumptions my not all be
universal. Here are some things that could go wrong:
-
Missing items. An IO
may be imported into a course and not have all of the resources it needs
to operate properly. The provider of the object may have assumed by that
certain standard files will be present such as JavaScript files. They
may not be.
-
Inability to access
files. Right name, wrong directory.
-
Misnamed files.
-
Filename collisions.
An instructional object may bring in files that have the same names as
other files in the course but are different
-
Communications
-
The learning or
content management system may not be able to accommodate multiple
instances of the same files or objects.
Bringing
new IOs into a course can raise unexpected problems. Removing an IO may
inadvertently remove resources needed by other IOs.

An
instructional object should run when it is placed in the appropriate
context, e.g., a course. It contains all of the resources it needs to
operate. Creating such an object is a challenge. You need to predict where
problems might arise. This gives us ideas about needs the SCO an
instructional object must satisfy.
3.2. The
target SCO
In
the context of SCORM a sharable content object (SCO, Figure 7) is intended
to be an instructional object (IO). I’ve repeated the figure for emphasis.
This is what we are shooting for. A SCO is intended to be a
specific type of instructional object. However, in implementing the SCORM
specifications a SCO may not conform to the intent of an
instructional object. What is a method for reliably creating an
object-like SCO? We want a SCO that is a complete autonomous instructional
object.
Figure 7. The target SCO
When
developing a course using a specification such as SCORM it is easy to
violate the concept of autonomy. Currently a SCO implemented in SCORM is
an abstraction. You can’t send me a "pure" SCO. You can send me a
content package with a manifest with resources that refer to files that
are in the package, locally or remotely available. You have to send me a
manifest to send me a SCO. How can an autonomous IO be created? SCORM and
its SCOs can support the creation of autonomous IOs.
Let
us look at the acronym "SCO." A SCO is a Sharable Content Object.
Those three words give us a starting point.
Sharable
This
means it is reusable elsewhere. To be truly sharable it must be possible
to:
-
Find
it
-
Know
what it is
-
Get
it
-
Put
it in a course
-
Run
it
With
the exception of "Run it" all of these also apply to Assets. This
document can be applied to resources of "asset" type.
Content
This
means it contains stuff, generally files or references to files or URLs.
["Stuff" is a vague term frequently used in the "content" world.] There
are no inherent limitations on what the stuff can do so long as it is
effectively contained within the SCO. The use of URLs local to the LMS is
not advised. They may not be stable and may be subject to changes
in the client/server relationship.
Object
The
stuff and the stuff that makes it work needs to be
encapsulated. It is in some way a whole. You
can pick it up, put it some place and it will work.
Right
now a SCO is not sharable, it has a modest content model and it is not an
object.
3.3. Current Model
Let’s
dig a little deeper. How do these terms interrelate? What is necessary to
make these factors work? This is where the rubber meets the road. To find
it and know what it is, you need some sort of information that is
available that tells you about the thing, either directly or through some
sort of proxy, e.g., a search tool. Descriptions of things, such as
objects (hey, we’ve seen that term before) with content (yet again!) are
done with good old metadata. To maintain the "objectness" it must
be possible to pull that metadata out of the object to look at it. Let’s
not worry how the implementation does that. It does, and probably puts it
in a database of some sort. The metadata has allowed me to find the SCO.
Now I need to find out if it is something I actually want. Unless the guy
in the next cubicle or I made it, I probably don’t know too much about
this thing. I probably searched by fields and or key words. Tell me about
yourself, SCO. You may ask for specific information such as the title and
description. Does it fill your need? Can you run it? You may ask for all
of the metadata: "Show me what you’ve got." In either case, you want more
of the metadata revealed. As long as something can get to the metadata, no
problem. In fact, the hosting system may have acquired the metadata in
advance, anticipating your every wish. You may be looking in a repository
that contains only metadata.
You
decide this is a SCO you want. You have negotiated the right to use it.
Get it. You ask the serving host to send it to you. This means you want
the object with its content. Ah ha! Here we are with the old question,
what is content? As above, it is the stuff and the stuff that makes it
work. What’s in the object? For simplicity’s sake, let’s take a standard
model:
-
Files that will run
in the user’s browser
-
Files that support
the other files:
-
Cascading
style sheets (files used by the files in this object and potentially
files in other objects)
-
JavaScript
files
-
Other
dependencies: media (files used by the files in this object and
potentially files in other objects)
-
Optionally/Optimally, a
SCO metadata file (yep, that’s where it lives for a SCO)
Notice
that thus far the SCO does not actually contain any content
(Figure 8). It is a directory system (or index) that defines a
starting point for using some files. It tells where
those files are located by using their names and a path (e.g.,
comm/) if appropriate. I’ll stay with the term "instructional element"
until we have something that is more object-like.
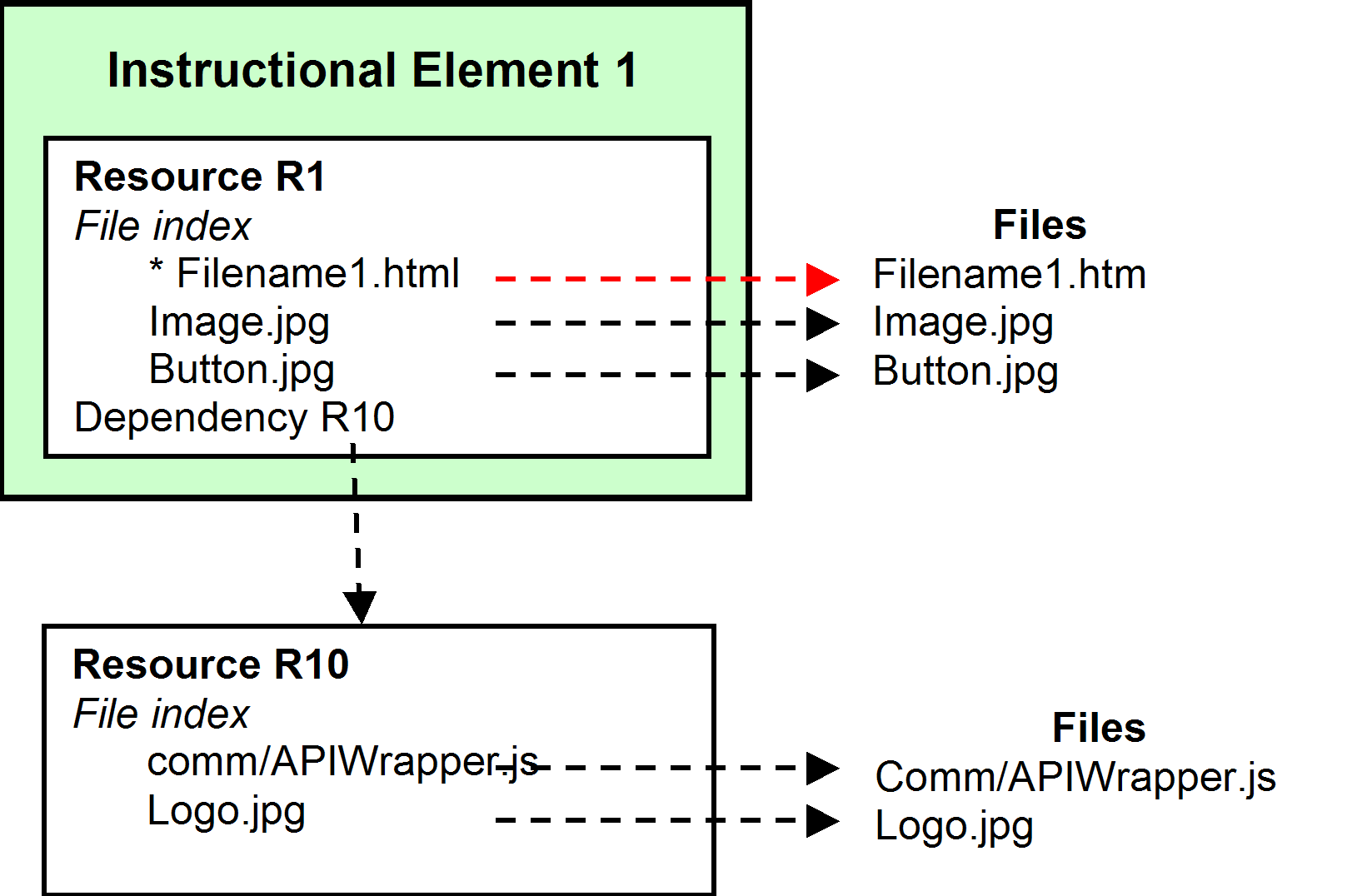
Figure 8. An instructional
element with a dependent resource and external files
In
SCORM the part that tells which files are going to be used and where they
are is a block of information in the manifest. Since we are talking
about SCORM, I’ll use the common binding for SCORM, XML.
This is not a tutorial on XML. You can find one of those elsewhere. I’ll
assume you know the basics of XML. The part of the element in the manifest
is called a "resource" of type (adltype) "sco." An asset of
"adltype=asset". An instructional element could use files that are common
to all of the other resources in the manifest. It is
dependent on those files. Those files could all be contained
in another resource. Here, with dependency, we have some real risks. They
break the autonomy of a potential object. The resource is using things
outside of itself. We have broken is encapsulation on the hope that
everyone else who put things into this course does it right. What if
someone overwrote one of the dependency files? What if they forgot to put
it there? Or put it in a subdirectory with another name? What if they
removed a SCO and in the process removed a needed file? If SCOs are going
to be truly reusable you can’t take this chance.
3.4. The
objective
Our
objective is to create a SCO that is a completely self-contained unit, or
nearly so. We would like to approach its being an object. An object
allows management and reuse without concern for filename collisions. It
allows editing of course structures by an instructional designer rather
than a programmer. It encourages an instructional object economy.
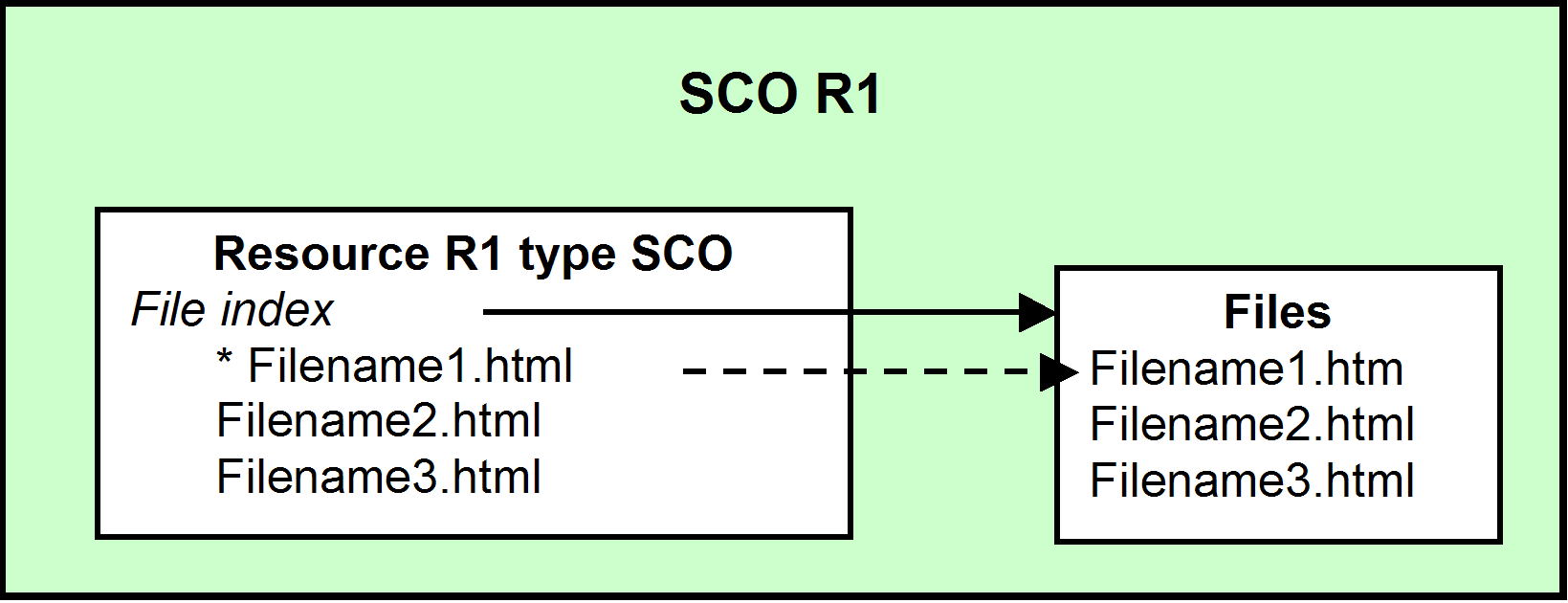
Figure 9. An object-like objective
4. The encapsulated SCO
Let
us move forward with the concept of an encapsulated SCO.
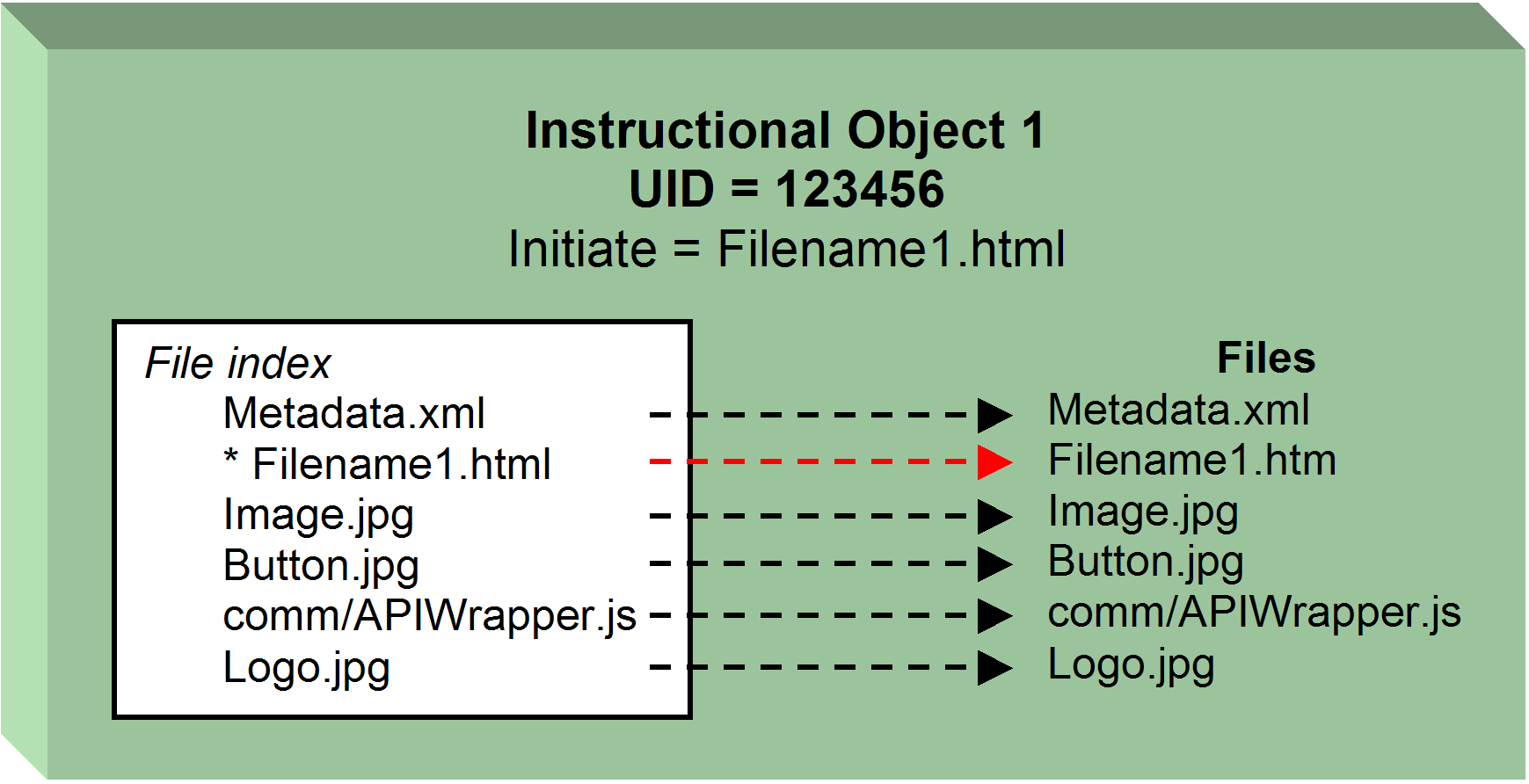
Figure 10. The target: an encapsulated
configuration
In
SCORM a SCO is defined in the manifest as a "resource" with an adlcp:scormtype="sco" attribute. A
SCO must support the LMS APIs of at least initiate and
terminate. An "asset"
may not support the LMS API. <resource>s are grouped within
the <resources> element
in the manifest.
Logically
this looks like Figure 11:
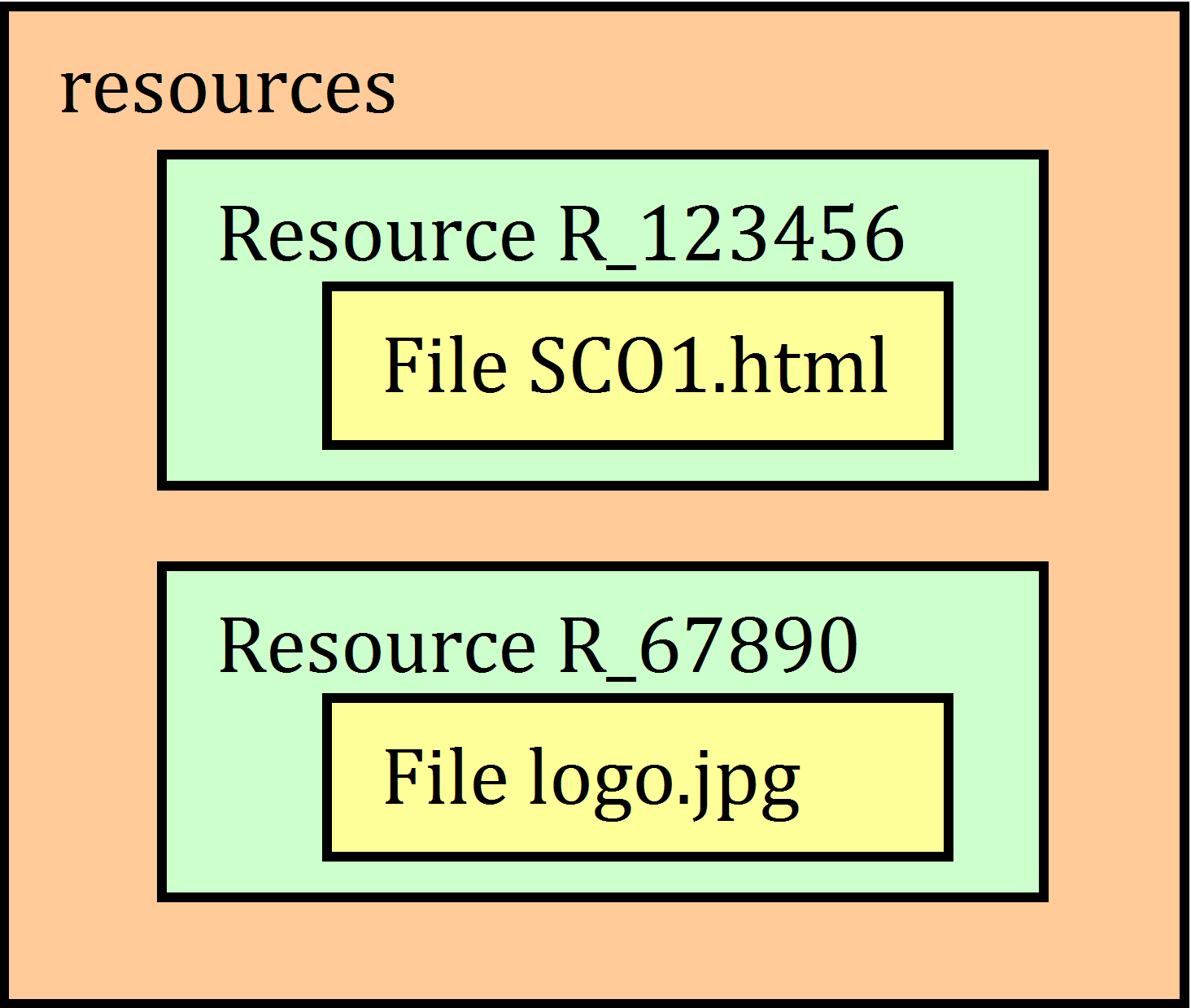
Figure 11. Logical
resources structure
In
the land of XML this translates to (Code 1):
Code 1. Resources in XML
<resources>
<resource identifier="R_123456"
type="webcontent"
adlcp:scormType="sco"
href="sco1.html">
<file href="sco1.html"/>
<dependency identifierref="R_67890/">
</resource>
<resource identifier="R_67890"
type="webcontent"
adlcp:scormType="asset"
href="logo.jpg">
<file href="logo.jpg"/>
</resource>
<resources>
Note: The attributes are shown in list form for ease of reading. Format is optional in XML. Each
<resource> is a SCO or an Asset. An Asset
hauls files around. For our current discussion, let’s leave out the Asset.
They are "file reference baskets." A SCO’s files do things,
communicating with the LMS. A SCO contains one or more file references.
The file isn’t actually contained in the resource. This is an
important point. The <file> designation contains a
reference to the actual file by name and path.
4.1. File consolidation
The
href attribute of the <resource> specifies the file
that should open in the browser when the SCO is started, in this case
Filename1.html. The SCO must
have code to contact the host LMS’s API, which it signals when it
is initiated and terminated. Typically the launch file HTML achieves this
by calling JavaScript code in an external file, e.g., APIWrapper.js. This
is often a commonly used file that may be referred to in a dependency
resource.
Let’s
look at that troublesome resource the instructional element is
dependent on (Figure 12). The problem is that the instructional
element is relying on two files that the instructional element resource
has no direct control over, APIWrapper.js and logo.jpg. Additionally one of those
files, APIWrapper.js, is
supposed to be loaded in a specific subdirectory, comm/. We can only hope that the
right things are where they ought to be. The instructional element points
to those external files indirectly. It uses a special type
of index member called "dependency." Dependency points to another resource
of type asset.
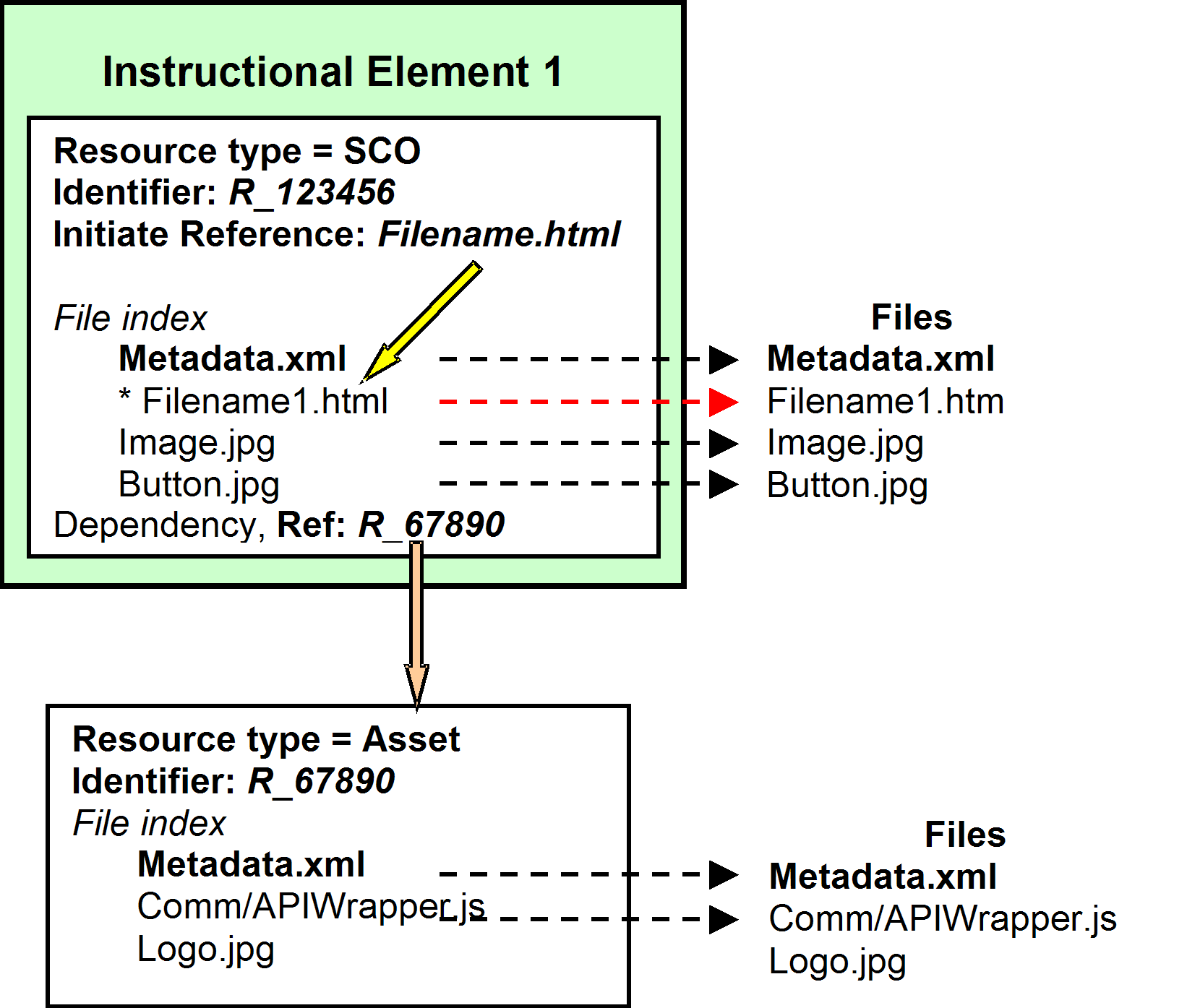
Figure 12. The SCORM SCO model.
As
you can see, the instructional element uses its resource with an
identifier R_123456 to point to another resource with an identifier
of R_67890 through a <dependency> element. The
instructional element may not use all of the files in the resource that
dependency points to. Why don’t we just pull all of those dependency files
needed and stuff them into our instructional element and its corresponding
group of files? We could do that. See Figure 13. Consolidated files.
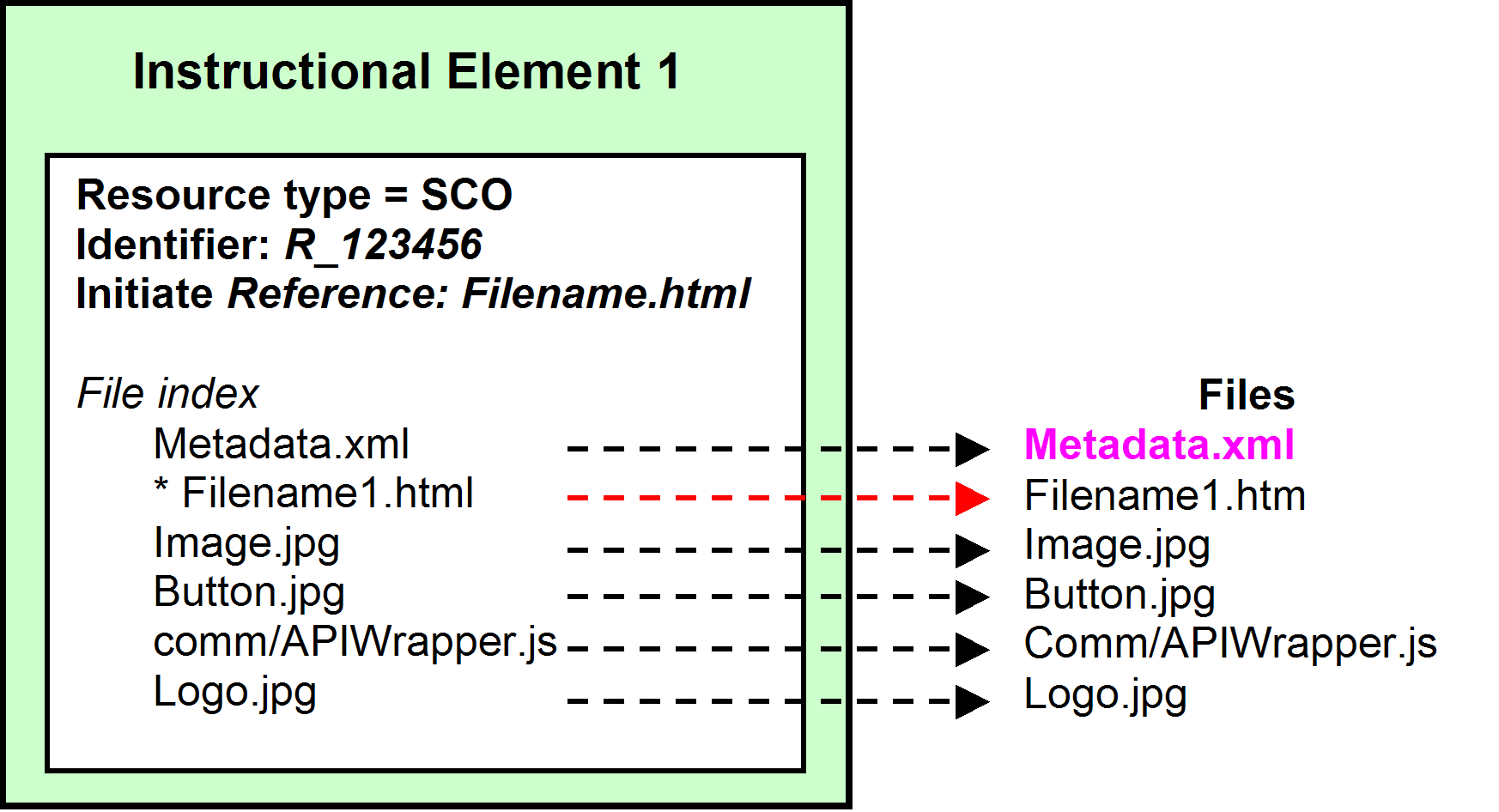
Figure 13. Consolidated
files
If
our consolidated instructional element puts all of its files in the root
directory, we have lost the advantage we just gained by referring to them
all in the single resource. Additionally, we still have the problem of the
potential collisions of files from different instructional elements with
the same name. If we put all of the instructional element’s files in a
separate directory then we don’t have to worry about any collisions. We
don’t have to worry about the common files being overwritten. The only
place we can create a reliable directory is under the course directory. If
we put it somewhere outside of the course directory we have to make an
absolute reference to it: http://... This is asking for trouble. It
requires that any place the course is run the same path is available from
the server top down to the desired specific directory. I doubt one could
get every LMS installation to agree to that. It is not a viable option. It
is not necessary. All you have to do is put the files in a unique
subdirectory under the course’s root directory. For convenience
sake you may want to use all or part of the instructional element’s
identifier as part of the directory name. Not necessary, but it could be
helpful (e.g., versioning). An easy way to do this is to create the
subdirectory and refer to it with the base path offset. Base adds a path prefix to the
filename. More about base later (4.2).
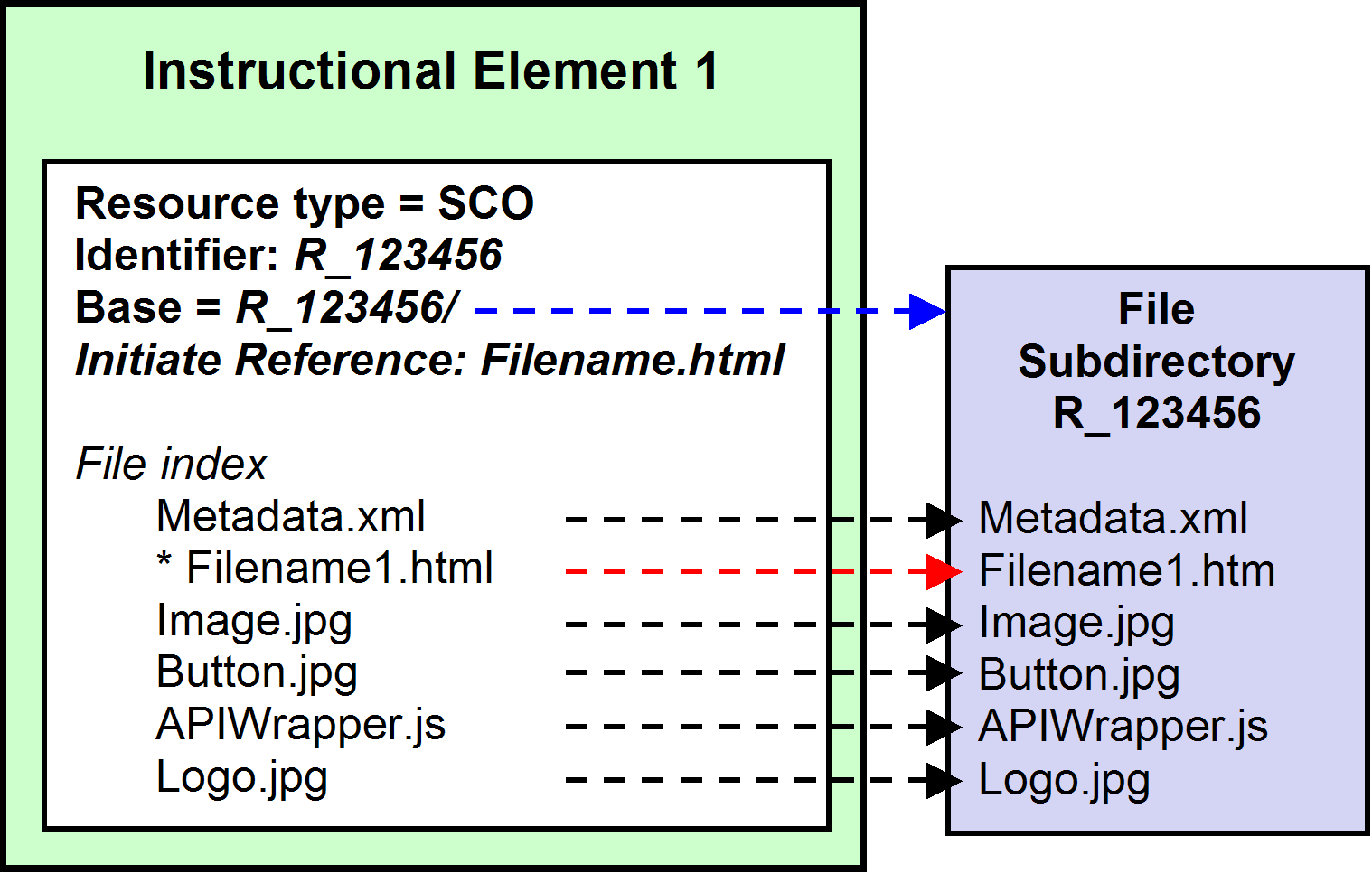
Figure 14. The resource - subdirectory pair.
Those
supporting files referred to by the dependency resource of type
Asset (R2) raise a question when it comes to reusability. What if several
instructional elements use the same files? We have taken them out of the
root directory. Later. It’s an optimization issue.
4.2. Files and
Directories
Resources
are pointed to (referenced ) by <item>s in a manifest. The
<resource> contains <file> elements that point to
the files. As we have discussed, the problem comes with the file names.
These may not be unique within a content package. The same may be
true of the dependency files. The files themselves aren’t actually in the
resource. They live somewhere else, namely in the course directory
allocated by the LMS or SCORM authoring tool. If all of the files for a
course are lumped in a common directory, how do you avoid collisions in
file names?
It
is inevitable that you will want to edit a web page or two at some time.
Think of the mess you can get into if they are all in one big directory
with weird unique names. Been there, done that. I am assuming you have
some sort of document management system, either an application or a
written policy that may require meaningful subdirectories. If not, you
could get in real trouble if you try to manage a fair number of courses.
Well, that’s YOUR problem. What’s that? Put the files in separate
subdirectories? Say, maybe we’ve got something there.
There
is another way to avoid file name collisions. Put the files associated
with a specific <resource> in their own
directory. Files will be unique by virtue of a unique path. When a
file is referred to only the subdirectory needs a unique name as
part of the path:
Code 2. Pointer relationships
<item identifierref> —> <resource identifier href=path/filename> —> file
This
is a method that can be used in the JISC Reload tool.
There
may be additional sub-directories within a resource’s directory. For
example, some developers may choose to place all of their images in an
images subdirectory,. The
JavaScript file(s), e.g., APIWrapper.js, may be placed in a
common, comm, subdirectory
under the SCO’s subdirectory. Such subdivisions can aid management of the
SCO in use. In the SCO’s HTML pages these files must be referred to using
relative URLs. Note: relative path addresses should not go "uphill" (refer
to a parent directory, see below). But how do you create separate paths
with unique directory names for each SCO? For example, if you are going to
have a large number of SCOs to manage, then directory names are apt to
collide if they are arbitrarily defined, e.g., by the developer. Again, we
get to the GUID issue. If you use the resource identifier’s value (e.g.,
R_123456) to make the directory name
(e.g., R_123456/), then your
automated processes can help you out. It does create problems however. Now
the directory names are meaningless. This can make it hard to edit the
content files because you may have trouble finding the directory with the
files you are looking for. The files have the names you put on them, but
how do you find them? I find that the search capabilities on a PC are good
enough that you don’t need to worry about it. You will remember frequently
used directories, otherwise, use the search. And this is from a compulsive
organizer. This a content management and database issue. A lookup table
could be helpful here, drawing title, description and other information
from the metadata. An Excel spreadsheet might do the job.
A
method used with HTML is to preface a file’s path with an upward
reference, i.e., ../, to move
up the directory hierarchy. This capability is now not allowed as a default in Microsoft servers (http://support.microsoft.com/kb/226474,
http://support.microsoft.com/kb/332117/,
http://learn.iis.net/page.aspx/566/classic-asp-parent-paths-are-disabled-by-default/,
http://ase.tufts.edu/its/webDtParentPaths.htm),
as it opens the system up to potential security violations. A
hacker could back up the directory to get to some core machine controls.
It is unlikely that all LMS server administrators will turn this
default condition off. We must assume that not all servers will allow this
upward parent path reference. You could omit base and put the full path on each
file; this reduces the robustness of the SCO’s integrity. Thus every file
accessed by the SCO must be in the resource directory or a
subdirectory.
The
content package and its manifest is a description of the relationships
among its constituents. Not all content management (CMS)and learning
management (LMS) systems have path parenting (../) limitations. The CMS and LMS are
free to implement those relationships in any way they wish. They may, for
instance, create maps or directories to content that is stored on a server
separate from the manifest or its run time equivalent. A course developer
may make the assumption that parent pathing will be resolved and construct
courses accordingly. This assumption is not guaranteed. The assumption may
not be consistent with the organization at the course creation end of the
process. We shall proceed with the most reliable interpretation,
namely that parent pathing is risky. Some of the issues are the same no
matter which method is used. Remember, we are trying to make
encapsulated, inventoriable, reusable SCOs.
The
directory structure looks something like this (Code 3):
Code 3. Sub-directory structure
Course
+-Content
¦+-R_123456
¦ ¦ +-metadata.xml
¦ ¦ +-sco1.html
¦ ¦ +-comm
¦ ¦ ¦ +-APIWrapper.js
¦ ¦ +-images
¦ ¦ +-logo.jpg
¦ +-R_12347
¦ ¦ +-metadata.xml, etc.
¦ +-R_12348
¦ ¦ +-metadata.xml, etc.
¦ +-R_12349
¦ ¦ +-metadata, etc.
You
can simplify the situation by using the "base" attribute.
4.3. Base
Putting
the same path in front of a lot of file names that are all in the same
directory can be tiresome—although that is what tools are for. One can use
the base attribute in the <resource> element to reduce
the load. Base is a W3C XML
recommendation: http://www.w3.org/TR/xmlbase/.
Base defines a path to all of the files the element
contains. It has the advantage of letting you move a directory or change
its name and only have to change the path reference in one place. Base
uses the URI syntax. This method has been specified by no less than Tim
Berners Lee, et al.: Uniform Resource Identifiers (URI): Generic
Syntax: http://www.ietf.org/rfc/rfc2396.txt.
You may bow now.
SCORM
addresses the use of base in
the CAM document (3.4.3.1. ). Base has lots of uses. Let’s stick to
the current topic, SCOs.
Code 4. Use of base attribute
<manifest>
<organizations>
<organization>
<item identifier="IR_123456" identifierref="R_123456">
</item>
</organization>
</organizations>
<resources>
<resource identifier="R_123456"
xml:base="R_123456/"
type="webcontent"
adlcp:scormType="sco"
href="sco1.htm">
<file href="sco1.html"/>
</resource>
</resources>
</manifest>
Use of base creates the reference
from <item identifier="IR_123456" ...
> to R_123456/sco1.html.(Code 4) sco1.html is in the R_123456/ directory. You get the
idea.
4.4. <dependency>
We
do not recommend the use of the <dependency> element. There is
a problem with base. You can’t
"climb uphill" (reference a parent directory) with a relative path
reference in SCORM. You can’t reference upward against the base declaration in the resource. You have dug a hole and you
can’t get out of it as base
will prefix any reference you make with the base path.
The
<dependency> element is
not of much use here. The resource would have to have the same path as the
SCO subdirectory so there is little point in creating the dependency’s
resource. It could be beneficial to put the files considered into a common
("comm") subdirectory within
the SCO directory. If someone should wish to make a tool for
optimizing a package after it is fully assembled into a
course, this might be useful. <dependency> requires the
presence of an additional <resource>. By not using
dependencies you end up with the entire SCO defined in one <resource>. This makes a
nice clean system to work with. It maintains SCO autonomy.

The
underling concept is to create fully self-contained SCOs that will
work no matter where they are used. Tools should take care of the
donkey work.
This
differs from the recommendation in the SCORM CAM, Section
3.6.2. Using the <dependency>
Element, that suggests the use of the element to reduce the
replication of files used by multiple SCOs. In this guideline, <dependency> is considered
useful in optimized content packages. A course could be
reconfigured for delivery. It may be useful once the standard course has
been developed. See Section 8, Standard, Consolidated and Optimized
Packages.
5. SCO
Metadata
Metadata
supports the use and management of SCOs. The following comments are
focused on those needs and do not reflect instructional factors that are
also important but apt to be of specific value to an entity. The ADL
Guidelines for making reusable content with SCORM 2004 covers those
topics. There are many metadata tools out there. As Eliot Christian of
USGS said, "Any metadata is infinitely better than none." Just do it. With
the right tool, once it is part of your work flow you will hardly notice
it. In addition to the <resource> element, the <file> element may also contain
the <metadata> element.
With a reasonable metadata tool you can call up information about a
SCO without having to open it. This may aid in the (re)use of individual
files in the SCO or Asset.
SCORM
uses the IEEE Learning Object Metadata (LOM) specification. The following
SCO ADL/LOM metadata elements are strongly recommended: (Code
5)
Code 5. Strongly recommended metadata
General>Identifier [catalog, entry]
General>Title [string]
The
recommended elements are (Code 6):
Code 6. Recommended metadata
General>Description [string]
Lifecycle>Version [string]
Also
recommended (Code 7):
Code 7. Also recommended metadata
Lifecycle>Contribute>[Role (editor), date)] (provides the last edit date)
An example
metadata file is provided in the Example section (13.2). The
metadata is the first element in the resource as defined in the CP
XML Schema (imscp_v1p1.xsd). The SCO’s
metadata file is placed in its file directory and pointed to by the
resource (Code 8):
Code 8. Pointing to the metadata
<resource
identifier="R_123456"
base="R_123456/"
type="webcontent"
adlcp:scormType="sco"
href="sco1.html">
<metadata>
<adlcp:location>metadata.xml</adlcp:location>
</metadata>
<file href="metadata.xml"/>
<file href="sco1.html">
<file href="images/logo.jpg">
<file href="comm/APIWrapper.js">
</resource>
Thus
the location of the metadata for resource R_123456 is R_123456/metadata.xml. This sort of
naming convention can make it easy for tools to find things and manipulate
them (see Section 11). It is not required however. It will work with
whatever naming you use. The keys are uniqueness of the
subdirectory names and of the <resource> identifiers.
The
metadata has some additional fields. You can read about them elsewhere
(ref: SCORM 2004 3rd Edition Content
Aggregation Model (CAM), Section 4). When possible metadata can be
developed as part of the work flow. A SCO has a title and description in
the storyboard phase of development. If these can be captured then the
metadata is started. Similar strategies can be useful for other fields.
Fields developed early can also contribute to quality assurance: What was
the plan for this SCO? Did it meet that plan? Metadata can be part of
project management, setting out the specifications for the SCO and work
assignments.
6. SCO
Uniqueness
Now
we get to some problems in reusability. You really want your
stuff to be "sharable." When you want something to be
reused, you want a rule set to follow that should be successful. You don’t
know if someone is going to reuse the SCO in a new context. The first
problem encountered is uniqueness of file names. How many
files might be named "introduction.html," "index.html" or "pix1.jpg?" You’ve named a file "index.html" so it will be easy to
find and edit. You have to plan to avoid a collision of names. You cannot
be sure your file name is unique in the larger world or in the manifest.
You don’t care to give it some long meaningless UID string for a file
name. Fortunately each resource refers to files that are all neatly tucked
into their own little subdirectories so filename duplication need not be a
problem. See Section 4.2. Files and Directories.

When
there are a lot of SCOs and/or SCOs made by different people there can be
identity collisions unless a standard identification method is
used.
6.1. Resource identifiers
A
<resource> XML element
has an identifier attribute.
This should have a value that is unique in the content package in which it
is used. This is a locally unique ID (LUID). Initially it may be a
"probably unique ID" (PUID) as discussed in Section 6.2. It may be useful
to draw from the identifier in the metadata to create this ID for
uniformity. That’s just a matter of style. If there is a resource ID
collision, all that needs to be done is to change the identifier attribute’s value in the
resource element. Using PUIDs
this would happen rarely. You will probably never encounter it.
6.2. Unique Identifiers
A
unique identifier is unique within some scope. Let’s talk about
four kinds of UID:
UUID:
Universally Unique ID
GUID:
Globally Unique ID
LUID:
Locally Unique ID
PUID:
Probably Unique ID
UUID
and GUID are essentially the same. Through an algorithm a long string is
generated that has an extremely high probability of being unique. A
globally unique ID can be up to 128 characters long. If you consider the
number of values each character can have (36) and the number of characters
(128), you can see that the number of possible IDs is astronomical
(36128). Some systems (e.g., the Handles system)
allocate specific prefix codes within those 128 characters. Additionally,
an organization may embed some identifiers with local meaning. Still, the
number of possibilities remains astronomical.
SCORM
2004 does not say much about unique identifiers (UIDs) for the metadata
<identifier> element:
4.2.2.1. <identifier> Element
"The
<identifier> element
represents a mechanism for assigning a globally unique label that
identifies the SCORM Content Model Component. The notion of assigning a
globally unique identifier to a component is important when dealing with
multiple facets of learning content development (e.g., versioning,
maintenance, etc.). "
Unique
IDs can be pretty well ensured with reasonable programming practices. It’s
not perfect, but very good unless someone does something stupid, e.g.,
uses only the date. An enterprise may choose to include some sort of
enterprise and entity ID within the GUID. No problem. There are algorithms
for generating GUIDs. I am not foolish or brave enough to recommend one.
You can look to Wikipedia as a start on this issue: http://en.wikipedia.org/wiki/Universally_Unique_Identifier
. The Handles system developed by CNRI is another starting place:
http://www.handle.net/. CORDRA
uses the Handles system (http://cordra.net/docs/applicationprofiles/uri/v1p00/ap-uri-v1p00.php)
putting you well along the way of being able to register your content in
CORDRA. A specification for a GUID is referred to by XML Base:
Open_Software_Foundation which, through a series of mergers, can now be
found in the Open Group: http://www.opengroup.org/.
The standards world is always shifting about as the winds change. The GUID
is limited to 128 characters. Have fun.
A
UID that is 128 characters long is unwieldy—and unnecessary—within a
constrained context. A locally unique ID (LUID) means that it is unique
within a specified scope. For example a resource’s identifier ID must be unique for each
use in a SCORM manifest . The developer is to ensure that this is so. This
brings us to the Probably Unique ID (PUID). PUID is not an official term
but we will find the idea useful. It reflects how most people develop a
locally unique ID. They randomly generate a relatively short identifier
that has a very high probability of being unique within the scope of use.
If you use only digits, which are easier to generate algorithmically, 8
characters give you 108 possible IDs. Collisions within a
manifest are highly unlikely even though a moderately fine-grained course
may have 50-100 SCOs. Six characters have been used here for illustrative
purposes. It can be useful to select the last characters of the metadata
<identifier> value to be
the locally unique ID. Consistency is good.
How
you handle the various identifiers is a matter of policy for the
enterprise. The important thing is to have a written policy. Or
better yet, institute it in tools and utilities (see Section 11.
Tools). This may be part of your work flow
considerations.
6.3. <identifier>
in the Metadata
Each
<resource> can—and
should—have <metadata>.
Ah, the dreaded metadata (Section 4.4. <dependency>). The
metadata in the SCO can use the <identifier> element to hold
the UID. The metadata is contained in the resource. Thus the resource contains its UID. The identifier should be a GUID.
Logically it is built like this (Code 9):
Code 9. SCO unique identifier in the metadata
resources
resource (SCO1)
metadata
identifier
file(s)
resource (SCO2)
metadata
identifier
file(s)
7. Making
SCOs
It
is important that a uniform structure for SCOs be used. It provides
opportunities both within the SCORM specification and outside of it. This
document does not discuss what content actually goes in a SCO and its
instructional quality. That is left for other discussions more relevant to
instructional designers. This is a technical discussion. We are close to
having our complete SCO as an isolated, autonomous object. We have a
two-part SCO (Figure 15).

Figure 15. The two-part SCO
7.1. SCOs in a Content
Package
A
resource’s files can be stored in a subdirectory, referred to with the
path (e.g., with base). Those
files need a unique subdirectory. To fulfill our objective of preventing
filename collisions within a content package. You can identify your
subdirectories uniquely with a good unique ID (UID). Look at
Section 6. Unique Identifiers. A useful method is to derive
the subdirectory name from the resource ID, e.g., for resource R_123456 the subdirectory is R_123456/. This makes it easy to
extract files from a resource, manipulate, and import them into an
indexing system and so forth. See more in the metadata section (5).
Now
make the SCO:
-
Put the unique ID in
the identifier in the metadata.
-
Put the metadata in
a separate file, e.g., metadata.xml.
-
Put it in the
resource’s subdirectory, e.g., R_123456/.
-
Put all of the
resource’s files in the subdirectory (R_123456/)and its subdirectories as
appropriate (e.g., R_123456/comm, R_123456/images).
We
have now created all of the parts of a SCO. We put the files in a
directory structure with our subdirectory, R_123456, containing all of the parts
needed to make the SCO work (Code 10):
Code 10. Resource subdirectory structure
+-Content
+-R_123456
¦ +-metadata.xml
¦ +-sco1.html
¦ +-comm
¦ ¦ +-APIWrapper.js
¦ +-images
¦ +-logo.jpg
+-R_12357 ¦ +-metadata.xml
. .
The
entire directory structure is wrapped up in the zip file with the
manifest. If you are only shipping SCOs around in a content package, with
the <organization>
element providing an index, the manifest will look something like
this (Code 11):
Code 11. Single SCO manifest
<manifest
identifier="SAMPLE1" version="1.3"
xml:base="mycontent/"
xmlns="http://www.imsglobal.org/xsd/imscp_v1p1"
xmlns:adlcp="http://www.adlnet.org/xsd/adlcp_v1p3"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.imsglobal.org/xsd/imscp_v1p1
imscp_v1p1.xsd
http://www.adlnet.org/xsd/adlcp_v1p3
adlcp_v1p3.xsd">
<metadata>
<schema>ADL SCORM</schema>
<schemaversion>2004 3rd Edition</schemaversion>
<lom:lom>
<lom:general>
<lom:title>
<lom:string language="en-US">
Title for the Package
</lom:string>
</lom:title>
</lom:general>
<lom:metaMetadata>
<lom:metadataSchema>LOMv1.0</lom:metadataSchema>
<lom:metadataSchema>ADLv1.0</lom:metadataSchema>
</lom:metaMetadata>
</lom:lom>
</metadata>
<organizations>
<organization>
<metadata/>
<item identifier="I_7890"
identifierref="R_123456"
isvisible="true">
<title>Indexed SCO</title>
</item>
</organization>
</organizations>
<resources>
<resource identifier="R_123456"
xml:base="R_123456/"
type="webcontent"
adlcp:scormType="sco"
href="sco1.htm"
isvisible="true">
<metadata>
<adlcp:location>metadata.xml</adlcp:location>
</metadata>
<file href="metadata.xml"/>
<file href="sco1.html"/>
<file href="comm/APIWrapper.js"/>
<file href="images/logo.jpg"/>
</resource>
</resources>
</manifest>
Each
SCO carries all that it needs to function. Each SCO is defined in
its <resource> that
contains references to the files and the metadata. Each SCO has a defined
(sub) directory that carries all of its necessary files. This subdirectory
is included in the base declaration in the <resource>.
The
metadata is the standard stuff. It is acceptable to have no <organization> under <organizations>. There would be
no course. This is legal. Thus, the manifest would contain the
descriptions of the SCOs and the references to the actual files needed.
The subdirectories under the main root directory are defined, most
effectively through base. All
path references are relative. An <organization> can be a useful
portion of a manifest that is only transporting SCOs. The <organization>’s <items> can contain pointers to
resources by identifiers. Items and sub-items in an <organization> can create a
directory of the resources. This could allow you to create an index
organizing your SCOs. The "index" may be useful for content management.
The
JavaScript implementing the SCORM API is not discussed in this document.
7.2. Assets
The
principles applied to <resource>s of type
SCO should also be applied to <resource>s of type
asset. An asset is like
a SCO except that it does not have to communicate with the LMS.
7.3. Unwrapping a
content package
Now
that a set of SCOs has been wrapped up in a content package, it is time to
unwrap the package and get to the goodies. Unzipping this file then puts
the manifest.xml at the root
level of a directory (with all of the schema files as needed). It creates
all of the unique subdirectories under the root directory with the files
for the resources in the proper subdirectories in an orderly manner. Each
SCO points to its appropriate subdirectory through the use of base. How is the <resource> section of the SCO
created? It can be extracted from the manifest in the content package.
This points out the inseparability of the SCO from the manifest in the
content package. It’s still not completely an object, is it? Patience. Or
jump to Section 9. The Compleat SCO.
8. Standard,
Consolidated and Optimized Packages
You
made a course using encapsulated SCOs. There might be a lot of
redundant files. You might like to trim the course down. We can
consider three forms of content packages: standard,
consolidated and optimized.

8.1. Standard form
A
lesson developed in a standard form has self-contained SCOs
(Code 12). In the standard form the SCOs’ files described in each <resource> are all
contained in a unique subdirectory. They have all of the files necessary
to run, including the supporting files, in the subdirectory. Supporting
files include the JavaScript files and cascading style sheets. These SCOs
are almost object-like, comprised of a single XML block (presuming an XML
binding) and a single (sub)directory of files. The subdirectory may
contain subdirectories, but conceptually they are all in one subdirectory.
A SCO in a standard form content package has no <dependency> section.
Course development and management are done in the standard form.
All SCOs are self-contained. They can be edited, added and deleted without
compromising any other SCOs or the package’s integrity. This is an
expression of the reusability of SCOs. A content package in the
standard form should run in a compliant LMS so it can be evaluated by an
ISD during development.
Code 12. Manifest in standard form
<manifest identifier="SAMPLE1" version="1.3"
xml:base="mycontent/"
xmlns="http://www.imsglobal.org/xsd/imscp_v1p1"
xmlns:adlcp="http://www.adlnet.org/xsd/adlcp_v1p3"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation=
"http://www.imsglobal.org/xsd/imscp_v1p1 imscp_v1p1.xsd
http://www.adlnet.org/xsd/adlcp_v1p3 adlcp_v1p3.xsd">
<metadata>
<schema>ADL SCORM</schema>
<schemaversion>2004 3rd Edition</schemaversion>
<lom:lom>
<lom:general>
<lom:title>
<lom:string language="en-US">
Title for the Package
</lom:string>
</lom:title>
</lom:general>
<lom:metaMetadata>
<lom:metadataSchema>LOMv1.0</lom:metadataSchema>
<lom:metadataSchema>ADLv1.0</lom:metadataSchema>
</lom:metaMetadata>
</lom:lom>
</metadata>
<organizations>
<organization>
<metadata/>
<item identifier="I_7890"
identifierref="R_123456"
isvisible="true">
<title>Indexed SCO</title>
</item>
<item identifier="I_7890"
identifierref="R_123457"
isvisible="true">
<title>Indexed SCO</title>
</item>
</organization>
</organizations>
<resources>
<resource identifier="R_123456"
xml:base="R_123456/"
type="webcontent"
adlcp:scormType="sco"
href="sco1.htm"
isvisible="true">
<metadata>
<adlcp:location>metadata.xml</adlcp:location>
</metadata>
<file href="metadata.xml"/>
<file href="sco1.html"/>
<file href="images/logo.jpg"/>
<file href="comm/APIWrapper.js"/>
<file href="comm/common.css"/>
</resource>
<resource identifier="R_123457"
xml:base="R_123457/"
type="webcontent"
adlcp:scormType="sco"
href="sco2.htm"
isvisible="true">
<metadata>
<adlcp:location>metadata.xml</adlcp:location>
</metadata>
<file href="metadata.xml"/>
<file href="sco2.html"/>
<file href="images/logo.jpg"/>
<file href="comm/APIWrapper.js"/>
<file href="comm/common.css"/>
</resource>
</resources>
</manifest>
The
<item>s in the manifest
will point to the separate <resource>s by <identifier>s. Files that are
different from the two SCOs must have different names. The file
directory structure under the toot directory would be as follows (Code
13):
Code 13. File directory for a standard form.
Course root
R_123456/sco1.html
R_123456/images/logo.jpg
R_123456/comm/APIWrapper.js
R_123456/comm/common.css
R_123457/sco2.html
R_123457/images/logo.jpg
R_123457/comm/APIWrapper.js
R_123457/comm/common.css
In
this tiny case only sco1.html
and sco2.html are different for
the two corresponding SCOs. This content package does not contain a
submanifest and should process normally by an LMS.
8.2. Consolidated form
The
consolidated form will reduce the redundancy of files transmitted. The
look and behavior of a SCO may be governed by support files such as
cascading style sheets and JavaScript files. When multiple SCOs are
gathered into one lesson it may be desirable to the SCOs to have the same
look and feel as possible. In some instances this can be managed by using
the same support files. This can be possible either because the providers
of SCOs have a common policy or through testing. For example, a utility
may test multiple CCSs to determine that the same classes are supported.
The designer may then execute consolidation rules and inspect the results.
The standard form is maintained while a new, consolidated version is
developed. The consolidated form maintains the package’s integrity with
separable SCOs that have common support files to the degree possible. It
might be feasible for an enterprise to convert incoming single SCOs to use
common support files. These may be stored I an enterprise’s internal
repository. A consolidated content package will run in a compliant LMS.
In
a consolidated form the common files in each SCO (e.g., Standard.css) are
all aligned. This may mean replacing some files in SCOs to get a common
appearance during presentation. The SCOs remain self-sufficient. Tools at
the vendor’s or the LMS could support caching by providing a list of the
frequently used common files. Codes that use an algorithm to a unique
meaningless value from all of the bytes in a file (e.g., CRCs) could be
used to ensure that files are indeed identical. This is outside the scope
of SCORM.
SCOs
can be reused within a course. If the media file is in a separate
SCO (or Asset) it can be reused without having to duplicate the file.
Instructional designers can be encouraged to break courses into smaller
SCOs, reusing the media SCO within the more finely grained flow. This
encourages the development of more interactive flexible courses, too.
Courses developed in consolidated forms will maintain the encapsulation
found in the standard form.
8.3. Optimized form
The
course in the standard form is the course source. The
optimized course is then a derived instantiation
using the standard structures as starting points. A course that has had
its internal content and directories reconfigured to reduce size and to
speed delivery is optimized. It may have <dependency>s. Optimization is
optional; a course should work fine without it, it is just
bigger. Course development is not performed on the optimized form.
Editing an optimized course has a high likelihood of
regression—an error occurring in an unexpected place.
Consolidation is a good intermediate stage.
In
this day and age, computer memory is cheap and bandwidth is fast. You are
creating standalone SCOs and building courses out of them. If multiple
SCOs in a course use some of the same files, the content package will have
duplicated files in different subdirectories. This package might have its
size reduced by reorganizing the content package’s resource designations
and the subdirectories to optimize the package. Optimization is an
opportunity for tools (see Section 11) with
optimization algorithms. Clearly a value-added proposition.
8.4. Common
subdirectory consolidation
Common
subdirectory consolidation can be useful in managing the
look-and-feel for the parts of a course. Presume a course is
divided into topics. Each topic has a summary. You would like all
summaries to look the same but to look different from the rest of
the material in the topics. You could consolidate all of the summaries
into a common subdirectory with its own cascading style sheets.
This
is an intermediate method for optimizing a content package by combining
some of the SCOs in common subdirectories. This approach will
reduce the redundancy of files in the content package. This is done
by merging the files of more than one SCO in a common subdirectory
(folder). To a degree the subdirectory acts as a conventional CP does at a
smaller scale, although it is not a submanifest. If two SCOs have
some files in common and all other files have different names (no filename
collisions other than metadata.xml and resource.xml) then all of the files
can be put in a common directory. There will be two <resource>s, one for each SCO.
Both <resource>s will use
the same base but have
different "href" entry files.
Combining
two resources, R_123456 and
R_123457 in a common
subdirectory of /R_123456 would
look like this (Code 14):
Code 14. Consolidated SCOs
<resources>
<resource identifier="R_123456"
xml:base="R_123450/"
type="webcontent"
adlcp:scormType="sco"
href="sco1.htm"
isvisible="true">
<metadata>
<adlcp:location>metadata.xml</adlcp:location>
</metadata>
<file href="metadata.xml"/>
<file href="sco1.html"/>
<file href="images/logo.jpg"/>
<file href="comm/APIWrapper.js"/>
<file href="comm/common.css"/>
</resource>
<resource identifier="R_123457"
xml:base="R_123450/"
type="webcontent"
adlcp:scormType="sco"
href="sco2.htm"
isvisible="true">
<metadata>
<adlcp:location>metadata.xml</adlcp:location>
</metadata>
<file href="metadata.xml"/>
<file href="sco2.html"/>
<file href="images/logo.jpg"/>
<file href="comm/APIWrapper.js"/>
<file href="comm/common.css"/>
</resource>
</resources>
The
<item>s in the manifest
will point to the separate <resource>s by <identifier>s. Files that are
different for the two SCOs must have different names. The file
directory structure would be as follows (Code 15):
Code 15. Consolidated SCO subdirectory
Course root
R_123450/sco1.html
R_123450/sco2.html
R_123450/images/logo.jpg
R_123450/comm/APIWrapper.js
R_123450/comm/common.css
In
this tiny case only sco1.html
and sco2.html are different for
the two SCOs. This approach will reduce the redundancy of files
transmitted. This content package does not contain a submanifest and
should process normally by an LMS.
R_123450 is the union of R_123456 and R_123457. Conceptually resources
R_123456 and R_123457 are "subclasses" of an
abstract resource class, R_123450. This should be undertaken
with caution. It is really a job for tools. The metadata.xml and resource.xml are removed unless they
are given unique names. Typically, these files are retained only in the
standard form as that is when they would be accessed. The resource.xml files could be used by a
tool to determine the contents of the single common directory. It might be
difficult to extract a SCO from this package. This is consistent
with the underlying multistage model: Instructional system designers
(ISDs) edit the standard form. Technical people and/or tools do
consolidation and optimization of the standard form.
When do you use the standard form? The consolidated form? The
optimized form?
The
same large media file may be used multiple times within a course. This is
a tempting target for optimization. If this file is referred to by
separate SCOs, the file will be repeated (barring optimization). Course
development strategies can reduce this impact. The common subdirectory
consolidation may also reduce repetition.
Don’t
try to extract SCOs from an optimized course. Go back to the standard or
consolidated form. If someone wants to buy a course that they will edit,
sell them the standard form. Treat it like source code. Version it. First
test a course in standard form. The core resources should retain
self-contained SCOs in the storage system. The standard course is saved.
The other forms are derived from it. Reliably going backward from an
optimized to a standard form is apt to fail—or at least not result in the
original standard form. The difficulty in extracting pure, original SCOs
from an optimized form can provide a low level of IPR support.
8.5. File
naming
Consolidation
and optimization will attempt to put SCOs that use the same support files
into common directories, possibly the root directory. Doing this requires
that the common files actually be either common or interchangeable and
that files unique to a SCO be uniquely named. Let us consider file names:
how do we avoid name collisions? We can tell people to use longer file
names and try to always include something in the name that is apt to make
it unique, e.g., F15elec01_introduction.html. This is
a good start but may be unreliable. Given human nature there are apt to be
any number of SCOs with files named "image01.jpg" or "Summary.html." An alternative is to
(automatically or manually) add random characters in the name, such as at
the end. The result is then something like image01_27a4.jpg. This adds a PUID
(probably unique ID) to the name. Just a few random characters greatly
increase the probability of uniqueness of the filename within one content
package, yet the name retains human readability. The objective is to
increase the level of effective consolidation and optimization through a
decrease in file name collisions. This is particularly important when SCOs
come from a variety of sources. It supports reuse of SCOs. Such a file
naming convention is only a suggestion. If optimization is not an
issue, then neither are file names as long as files within a SCO are
unique named.
8.6. Objects
versus programming policies
Some
may prefer not to use a SCO object model. This requires
standard programming policies. If SCO and course development are
tightly controlled within an organization this can work. There must be
strict naming conventions for files, both SCO specific and common.
Non-"object" SCOs cannot be reliably exchanged with other organizations in
a risk-free manner. There will be a temptation to make larger SCOs because
reuse is less of an issue. A policies model can incorporate some runtime
efficiencies from the start. Common files can be used. It ids possible to
use unique subdirectories for files within a resource, prefixing each
filename with the path. A problem is that it requires instructional
designers to have an awareness of the underlying XML, work that should be
buried in the tool. It also makes it difficult to reuse a SCO by editing
it, for in creating it new file names and/or directories must be
developed. With proper policies some of these difficulties can be
overcome. The result can be streamlined courses with few redundancies of
files.
The
object approach can lead to "fat" courses with considerable redundancy of
files. An optimization tool or utility can convert a fat object course
into a more streamlined non-object course. It would probably be very
difficult to go from a non-object course to a standard object course. A
standard course model has more nearly object-oriented SCOs. A SCO can be
placed in a minimal manifest framework and run through a RTE for testing.
Thus, individual SCOs can be tested before integrating them into a full
course. The difficulty is in making an optimization tool. It is
non-trivial. Many programmers will have neither the inclination nor time
to do it. It could be a strong tool in the marketplace, however. Whatever
the case, the fat course should always run properly, although it may be a
bit slow

8.7. Deployment and
Versioning
Courses
are deployed to CMSs and LMSs for subsequent delivery to learners.
Constitutes may be used in more than one course or more than one edition
of a course. The courses, or their constituents may undergo versioning.
The three forms, standard, consolidated and optimized differ with respect
to deployment and versioning. The standard form has distinctly separate
SCOs. For a very large course, the SCOs can be deployed in a set of
content packages, breaking the course into more manageable size pieces for
transmission. The SCOs are independent; the course can be safely
reassembled at the receiving end. Individual SCOs can be updated and
deployed to replace previous versions. The separate SCOs can be used in
more than one addition of a course. This is subject to agreements between
the course provider and the course deliverer. The penalty is a potentially
larger total size if there are redundant SCOs.
The
consolidated form may still have manageable blocks. A set of resources
will use a common resource block. This can be treated as a "super-SCO,"
affording course division for delivery, editioning and versioning. The
optimized form may or may not be subdivisible. The form to be deployed is
subject to policies and negotiations among the parties involved.
9. The
Compleat SCO
Compleat: An archaic form of
complete. "Compleat" has a
richer connotation of capability than the modern form, "complete." We can have a complete kitchen. We may have a compleat chef. The most common
reference to "compleat" is to Izaak Walton’s The
Compleat Angler (1653).
Let
us now move to the compleat SCO, a SCO that moves toward the
autonomy of an object. We have discussed the SCO in the
content package. We have included the metadata. We have not used <dependency>. We are using an
ID that is unique enough for the situation. We have set the files aside in
a subdirectory using xml:base.
We still don’t have an "object" that can be neatly tied up in the manifest
in a single piece beyond wrapping the pieces up in one zip file. At this
point the SCO has two parts: the subdirectory of files and the
<resource> section
in the manifest. As a suggestion—and only a suggestion—it
might be useful to put the <resource> information in the
subdirectory as an XML file so that it could be extracted easily to be
included in the manifest. This block could be placed in a file named resource.xml. It is a fragment of the
resources section of the manifest. The resource.xml file defines the
contents of the subdirectory. That file would be placed in the
subdirectory. This is allowed within the specification. To ensure that it
travels with the SCO when it is unwrapped it would be included in the
<resource> definition
itself:
Code 16. The Compleat SCO
<resource identifier="R_123456"
xml:base="R_123456/"
type="webcontent"
adlcp:scormType="sco"
href="sco1.htm"
isvisible="true">
<metadata>
<adlcp:location>metadata.xml</adlcp:location>
</metadata>
<file href="resource.xml"/>
<file href="metadata.xml"/>
<file href="sco1.html"/>
<file href="comm/APIWrapper.js"/>
<file href="images/logo.jpg"/>
</resource>
The
inclusion of the resource.xml
file allows zipping up only the subdirectory to create a completely
defined SCO. The <resource> section is defined
in the subdirectory. That file can be opened and pasted into the <resources> section of a new
manifest when a course is being developed. The <resource> section for this SCO
is going to have to be developed or extracted anyway. We might as well
make it easy. The uniform naming of resource.xml means that a utility can
look for that file. If it is not there, it can look for the file elsewhere
or it can get it from the manifest by matching up the base and
subdirectory if the SCO is in a content package.
As
you would imagine, the subdirectory now looks like this (Code 17):
Code 17. The Compleat SCO’s subdirectory
+-Content
+-R_123456
¦ +-metadata.xml
¦ +-resource.xml
¦ +-sco1.html
¦ +-comm
¦ ¦ +-APIWrapper.js
¦ +-images
¦ +-logo.jpg
This
embellished version of the SCO will NOT be included in the final examples.
It is not required. If you think it is useful, do it.
The space taken is small. If nothing else, it gives a level of insurance
that the SCO information can be recovered. This strategy allows you to
unzip the SCO alone directly into the course directory, letting it form
its own subdirectory with the resource information included. The
Isolated SCO described in Section 10 could use this
self-defining SCO to advantage.
10. The
Isolated SCO: Outside of the specification
Forward
legacy -- Remember the initial question, "If I ask you to send me a
SCO, what do you send me?" It is possible to make an isolated SCO
that you could send me. This is not in the specification, but if
you build SCOs as above that are within the specification, it is but a
small step to the isolated SCO. The discussion in Section 9 The
Compleat SCO describes a method for capturing the <resource> definition to allow
a more complete encapsulation of a single SCO. We could go outside
of the content packaging specification and zip up a single subdirectory
including a resource.xml file.
This creates a SCO as object-like. It is something you can send to
me. I can unwrap it and use it. This individual encapsulation is
not, repeat NOT, part of the specification. It is here
because it can be useful for content management and SCO
reuse. It can only be done by an agreement among participating
parties. Content Packaging with a manifest is always a more generalized
solution, but it requires unwrapping the whole package to get at what you
might want. It makes it hard to put a SCO "on the shelf." In the isolated
configuration the file is unzipped, the resource.xml file is opened and
copied. The copy is pasted into the resources part of the manifest and the
importation is complete into the standard form.
There
are limitations in creating such a singular SCO. Dependency files in each
SCO are contained in its directory. This may cause redundancy in the
overall package of SCOs. Don’t try to get fancy in trying to use one set
of dependency files for a bunch of SCOs to reduce redundancy. You will
only open yourself up to problems. As stated in the Q&A, don’t
confound SCOs with optimization. A course is
built with SCOs. Course optimization may be used, as described above.
Recognize the difference between a standard (source code ) and optimized
(operating code) course as you would with a compiler.
The
isolated SCO looks more object-like to other specifications. Conversion
should be manageable. The metadata is well isolated so it can be accessed.
It is not that the SCORM 1.X SCO will run directly in some other standard,
but that simple software utilities can convert it to that format. And the
other way around.
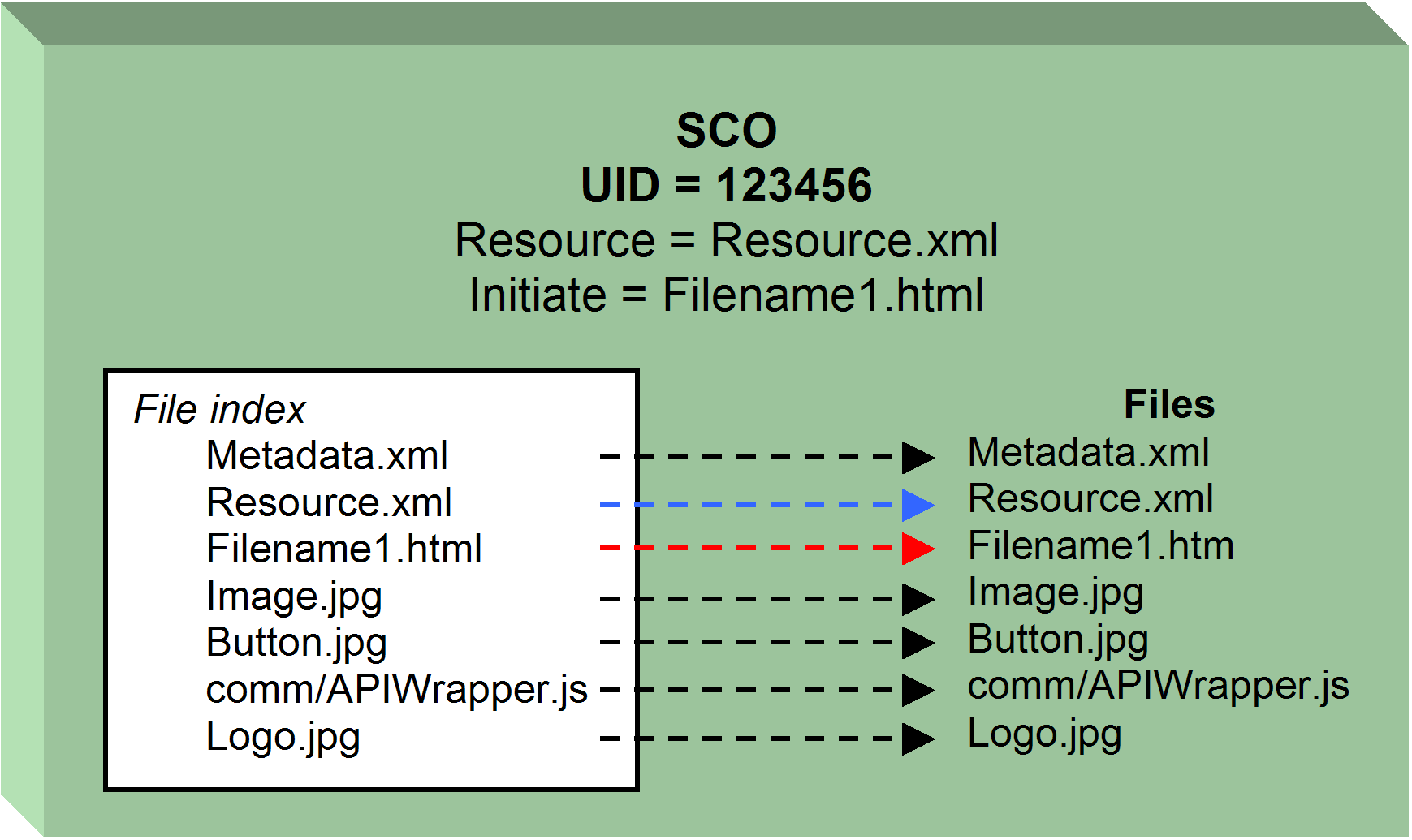
Figure 16. An encapsulated configuration
Again,
the isolated SCO is NOT part of the specification but could be useful for
managing SCOs locally. Tools and utilities would help you do this.
The
isolated SCO would most readily be adopted within an organization for SCO
management. SCO transactions between enterprises would entail agreement to
use something like this. An objective here is to describe something that
could be readily implemented, hence help build up the traffic in SCOs.
Specifications can grow by consensus based on common practice. NIST
considers this good.
11. Tools
Tools
are part of this discussion. It makes little sense to automate the
delivery of instruction without automating the processes of
developing instruction. Specifications can usually be
implemented in several ways. Automation supported development relies on
consistent and useable forms. Using standards effectively is all about
tools. The standards and tools achieve adoption hand-in-hand. Good tools
are a strong value proposition for vendors if specifications are
uniformly implemented. The user is interested in the front end. Does it
describe what the user wants to do? Is it easy to use? The back end
produces the messy code that no one really wants to look at. All they care
about is: Does it work? Does the course run? The technical people
care about the details of the actual mess that is produced. Therefore when
evaluating tools one of the things you want to do is have the technical
people evaluate what comes out the back. This is more than simply having
them test it against a reference LMS. They need to get into the output to
see if it is going to be robust. How hard will it be to support changes in
the specifications? Somehow get a technical person into the loop when
acquiring tools. Do this and you long reap the rewards. This guideline is
intended to provide a method for evaluating the function of some tools.
Tool opportunities:
SCORM
1.2
SCORM
2004 (sequenced)
Course
Item
Resource
Course
management
SCO
management
Content
management
Standard
package
Optimized
package
SCO
These
are opportunities singularly and in combinations.
12. Conclusion
A
common method for creating SCOs has been defined. If SCOs are constituted
in this fashion, one creates proto-objects that support a specific kind of
backwards/forwards compatibility for other (including new) standards. The
SCO will run on existing LMSs. The SCOs can be converted to support
another specification with simple utilities operating on consistent
"objects." Consider this a form of proactive forward compatibility.
This
is not rocket science. The objective is to create SCOs that can be treated
like objects. The <resource> declaration of the
SCO and its corresponding subdirectory containing the files it is
dependent on can all be wrapped up into a zip file that has a manifest
file. This is a convenient way to manage SCOs as single objects. When
unzipped in the root directory of a course, the new <resource>s are placed in the
<resources> section of
the manifest. The files themselves, in their dedicated subdirectories will
be just where they need to be. If you want to remove the SCO, once the
<resource> is identified,
the corresponding subdirectory is easily found. It is possible to merge
several content packages by combining the <resource>s in the <resources> section and
combining all of the files in their subdirectories under the same root
directory. This is the sort of thing that utilities do. Don’t try
to be clever by trying to share common files. That is a separate topic
left to final course compilation: optimization. You will be fine
even if you never optimize.
A
content package can be used to ship around SCOs. We saw that as an initial
issue: SCOs only really exist in a <manifest>. A manifest can be
created that is minimal. It will have minimal metadata identifying the
collection of SCOs. It may have an <organizations> with no <organization> in it. The <resources> section will
contain all of the SCO <resource>s. The directory
system with all of the files, neatly in their subdirectories, is zipped up
with the manifest with any control files desired (lom.xsd and so forth). When it
reaches its destination, it is unzipped in a directory and—voila!—there
are all of the SCOs!
13. Example
13.1. Manifest
The
following is a manifest with a two-page course using two SCOs, R_123456 and R_123457, each with one file sco01.html, sco02.html, that uses some other
files. Both have a metadata file. The sequencing block causes the
presentation to flow from SCO1, R_123456, to SCO2, R_123457. This is example is not
optimized. The SCOs are not in compleat form.
Code 18. Example manifest
<?xml version= "1.0" encoding="UTF-8" standalone="yes" ?>
<manifest identifier="SCO_TW01" version="1.0"
xml:base="mycontent/"
xmlns="http://www.imsglobal.org/xsd/imscp_v1p1"
xmlns:adlcp="http://www.adlnet.org/xsd/adlcp_v1p3"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation=
"http://www.imsglobal.org/xsd/imscp_v1p1 imscp_v1p1.xsd
http://www.adlnet.org/xsd/adlcp_v1p3 adlcp_v1p3.xsd">
<metadata>
<schema>ADL SCORM</schema>
<schemaversion>2004 3rd Edition</schemaversion>
<lom:lom>
<lom:general>
<lom:title>
<lom:string language="en-US">
Title for the Package
</lom:string>
</lom:title>
</lom:general>
<lom:metaMetadata>
<lom:metadataSchema>LOMv1.0</lom:metadataSchema>
<lom:metadataSchema>ADLv1.0</lom:metadataSchema>
</lom:metaMetadata>
</lom:lom>
</metadata>
<organizations>
<organization>
<item identifier="I_7890"
identifierref="R_123456"
isvisible="true">
<title>First SCO</title>
</item>
<item identifier="I_7891"
identifierref="R_123457"
isvisible="true">
<title>Second SCO</title>
</item>
<imsss:sequencing>
<imsss:controlMode
choice="false"
choiceExit="false"
flow="true"
forwardOnly="true"/>
</imsss:sequencing>
</organization>
</organizations>
<resources>
<resource identifier="R_123456"
xml:base="R_123456/"
type="webcontent"
adlcp:scormType="sco"
href="sco1.htm"
isvisible="true">
<metadata>
<adlcp:location>metadata.xml</adlcp:location>
</metadata>
<file href="metadata.xml"/>
<file href="sco1.html"/>
<file href="images/logo.jpg"/>
<file href="comm/APIWrapper.js"/>
</resource>
<resource identifier="R_123457"
xml:base="R_123457/"
type="webcontent"
adlcp:scormType="sco"
href="sco2.htm"
isvisible="true">
<metadata>
<adlcp:location>metadata.xml</adlcp:location>
</metadata>
<file href="metadata.xml"/>
<file href="sco2.html"/>
<file href="images/logo.jpg"/>
<file href="comm/APIWrapper.js"/>
</resource>
</resources>
</manifest>
This
looks like a lot of freight for two SCOs, but the overhead at the top is
only needed once. You can put in many SCOs.
13.2. Metadata
The
general form of the resource metadata file metadata.xml is:
Code 19. Example resource metadata
<?xml version="1.0" encoding="utf-8"?>
<lom xmlns="http://ltsc.ieee.org/xsd/LOM" xmlns:lom="http://ltsc.ieee.org/xsd/LOM"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://ltsc.ieee.org/xsd/LOM
http://ltsc.ieee.org/xsd/lomv1.0/lomLoose.xsd">
<general>
<identifier>
<catalog>ADL-ID</catalog>
<entry>A1B2C3DE123456</entry>
</identifier>
<title>
<string language="en">The Technical Content Object</string>
</title>
<language>en</language>
<description>
<string language="en">
A guide to learning content objects and their construction
</string>
</description>
<keyword>
<string language="en">SCO</string>
</keyword>
</general>
<metaMetadata>
<metadataSchema>IEEE LOM 1.0</metadataSchema>
<metadataSchema>ADLv1.0</metadataSchema>
</metaMetadata>
<lifeCycle>
<version>
<string language="x-none">1.0</string>
</version>
<status>
<source>LOMv1.0</source>
<value>draft</value>
</status>
<contribute>
<role>
<source>LOMv1.0</source>
<value>creator</value>
</role>
<!-- vCard for Tom Wason -->
<entity>
BEGIN:VCARD
VERSION:2.1
N:Wason;Tom
FN:Tom Wason
ORG:Wason Consulting
TEL;CELL;VOICE:919.602.6370
EMAIL;PREF;INTERNET:wason@mindspring.com
END:VCARD
</entity>
<date>
<dateTime>20091215</dateTime>
</date>
</contribute>
</lifeCycle>
</lom>
Don’t
let that vCard stuff scare you.
It is easy to make. Open up a contact in MS Outlook. Click
"File". Click "Export to vCard". Select a file name and
location to save it in and you’ve got it. Open the resulting file with any
text editor (e.g., Notepad). Delete lines if you want to. Cut and
paste the result into your metadata file. Of course a tool could
automate much of this...
13.3. Files in
directories
The
following files are placed in the appropriate subdirectories under the
root:
Code 20. Example resource directory
Course Root
R_123456/metadata.xml
R_123456/sco1.html
R_123456/images/logo.jpg
R_123456/comm/APIWrapper.js
R_123457/metadata.xml
R_123457/sco2.html
R_123457/images/logo.jpg
R_123457/comm/APIWrapper.js
13.4. A resource.xml file
If
resource.xml files were implemented the file for the sco1 resource
could look as follows:
Code 21. Example resource.xml file
<resource
identifier="R_123456"
xml:base="R_123456/"
type="webcontent"
adlcp:scormType="sco"
href="sco1.htm"
isvisible="true">
<metadata>
<adlcp:location>metadata.xml</adlcp:location>
</metadata>
<file href="resource.xml"/>
<file href="metadata.xml"/>
<file href="sco1.html"/>
<file href="images/logo.jpg"/>
<file href="comm/APIWrapper.js"/>
</resource>
Author:
| 